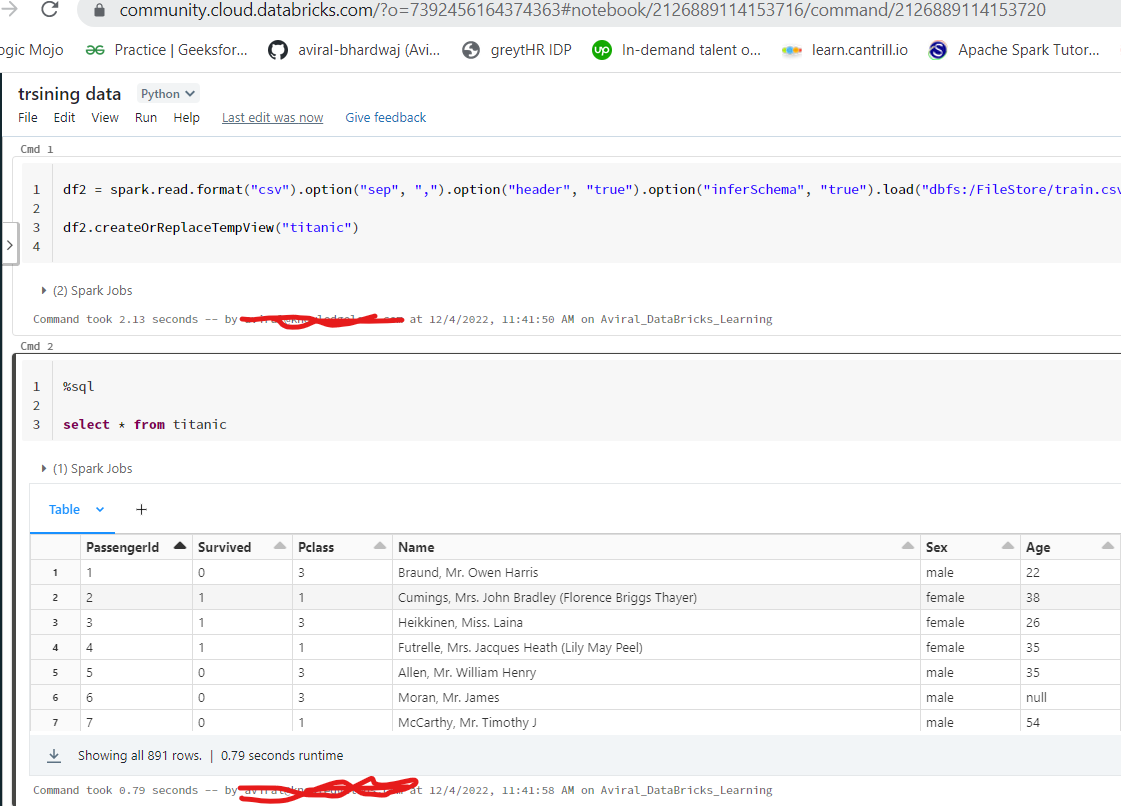
var df2 = spark.read
.format("csv")
.option("sep", ",")
.option("header", "true")
.option("inferSchema", "true")
.load("src/main/resources/datasets/titanic.csv")
df2.createOrReplaceTempView("titanic")
spark.table("titanic").cache()
spark.sql("Analyze table titanic compute statistics for all columns")
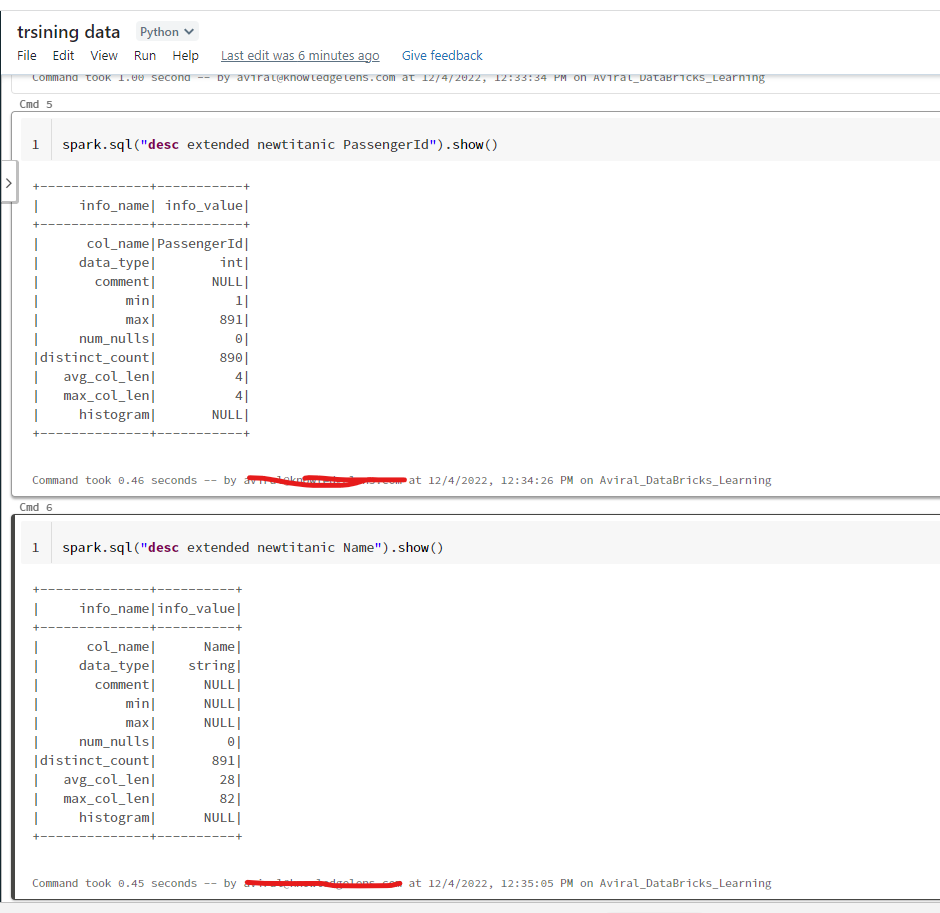
spark.sql("desc extended titanic Name").show(100, false)
I have created a spark session, imported a dataset and then trying to register it as a temp table, upon using analyze command i gett all statistics value as NULL for all column.
+--------------+----------+
|info_name |info_value|
+--------------+----------+
|col_name |Name |
|data_type |string |
|comment |NULL |
|min |NULL |
|max |NULL |
|num_nulls |NULL |
|distinct_count|NULL |
|avg_col_len |NULL |
|max_col_len |NULL |
|histogram |NULL |
+--------------+----------+
Can someone suggest what is it that i am doing wrong.
The thing I noticed is if i make a new table
spark.sql("create table newtitanic as select * from titanic")
spark.sql("Analyze table newtitanic compute statistics for all columns")
spark.sql("desc extended newtitanic Name").show(130, false)
this will fetch me statistics for all columns.









{kind=link}
{kind=link}