Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: AppendDataExecV1 Taking a lot of time
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
AppendDataExecV1 Taking a lot of time
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-04-2023 07:47 AM
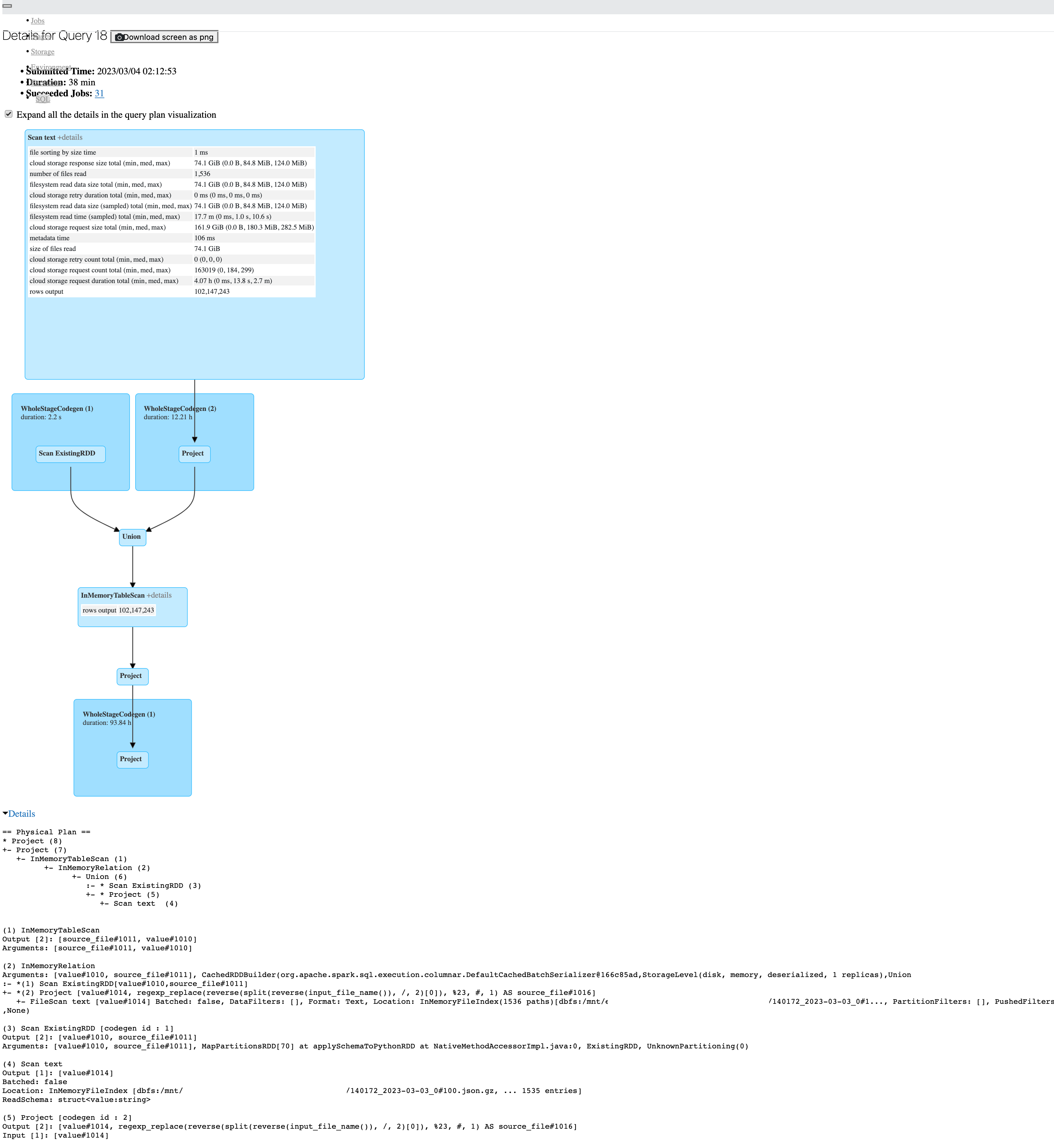
Hi, I have a Pyspark job that takes about an hour to complete, when looking at the SQL tab on Spark UI I see this:

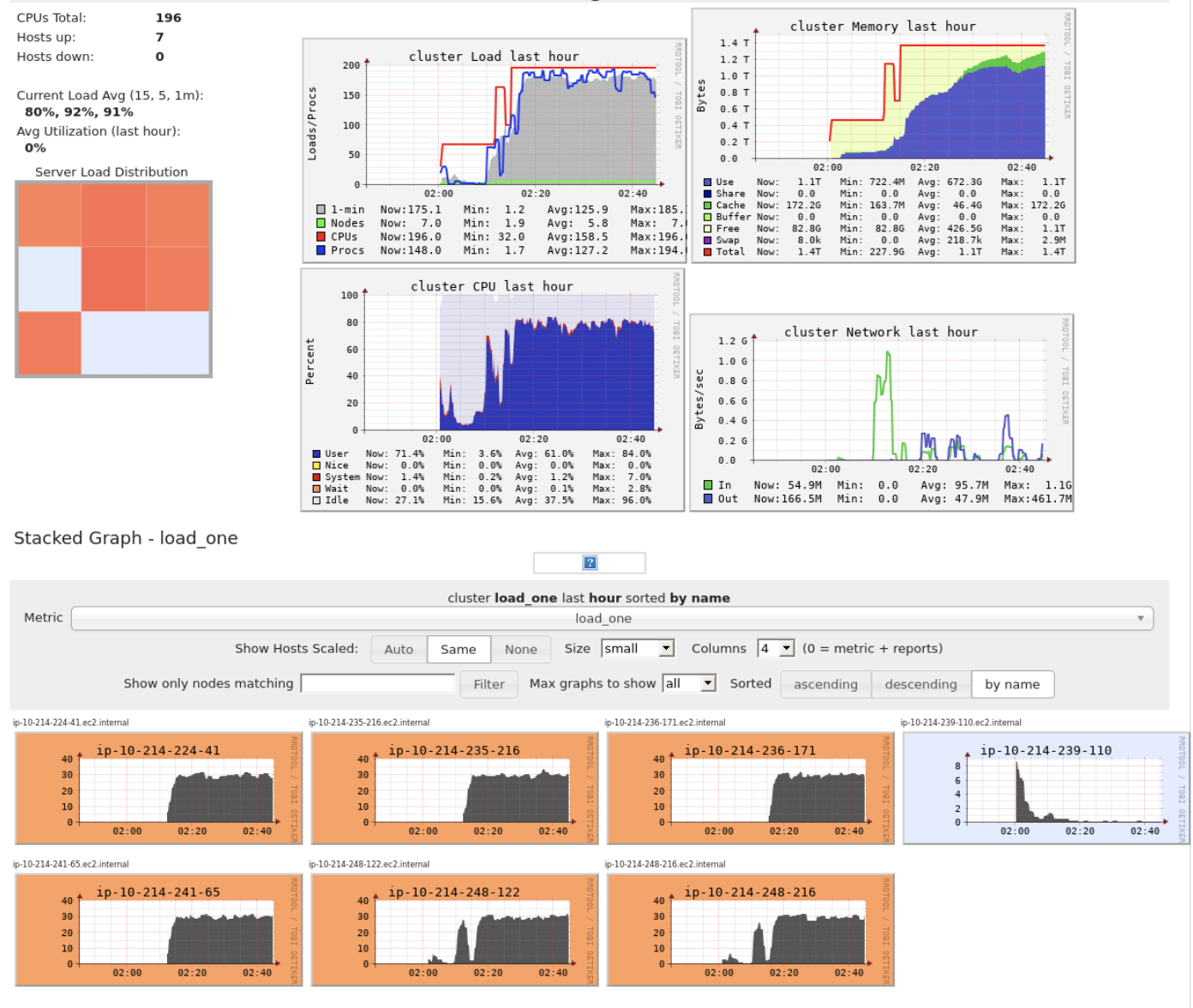
This is Ganglia for that period (the last snapshot, will look into a live run for the last part)
And the details, fields, and database names were replaced by placeholders or "..." for compliance purposes
== Physical Plan ==
AppendDataExecV1 (1)
(1) AppendDataExecV1
Arguments: [num_affected_rows#1348L, num_inserted_rows#1349L], DeltaTableV2(org.apache.spark.sql.SparkSession@7ecdf898,dbfs:/mnt/eterlake/...../...,Some(CatalogTable(
Database: database
Table: table
Owner: (Basic token.....
Created Time: Sat Jul 13 16:06:20 UTC 2019
Last Access: UNKNOWN
Created By: Spark 2.4.0
Type: EXTERNAL
Provider: DELTA
Table Properties: [delta.lastCommitTimestamp=1662525805000, delta.lastUpdateVersion=8134, delta.minReaderVersion=1, delta.minWriterVersion=2]
Statistics: 0 bytes, 6260684735 rows
Location: dbfs:/mnt/.../location/...
Serde Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.SequenceFileInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
Schema: root
......
.....
.....
)),Some(spark_catalog.......),None,Map(),org.apache.spark.sql.util.CaseInsensitiveStringMap@1f), Project [... 26 more fields], org.apache.spark.sql.execution.datasources.v2.DataSourceV2Strategy$$Lambda$8007/1446072698@7a714f29, com.databricks.sql.transaction.tahoe.catalog.WriteIntoDeltaBuilder$$anon$1@1df0da7eDo you see something that could be improved here?
Thanks!!!
Labels:
- Labels:
-
SQL


4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-05-2023 11:04 PM
@Alejandro Martinez
I would recommend you to go through this video:
https://www.youtube.com/watch?v=daXEp4HmS-E
Especially look through partitions, data skew, spills.
Also IMO the utilization (avg load) should be around 70%. Try to optimize your workload a little bit.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-06-2023 07:18 AM
Will look into that! thanks, really is a very simple process, the regex seems to be what is taking more time, that and the AppendDataExecV1. This is the other task that takes 38 minutes. The logic of the regex is this
dataframe = self.spark.read \
.text(source_files_path) \
.withColumn('source_file', source_file_derivation)
where source_file_derivation is:
source_file_derivation = regexp_replace(reverse(split(reverse(input_file_name()), '/')[0]), '%23', '#')
To add the filename on a column of the data frame (we read multiple files).
Thanks!

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-07-2023 09:39 PM
Hi,
When you say it is taking a lot of time, was there a situation where this was running earlier than the time taking now?
Also, approximately how much amount of data is getting processes with this JOB?
Is it consistently taking this much time?
Could you also please confirm about the cluster configuration (also the DBR version?) this is running on?
Also please tag @Debayan with your next response which will notify me, Thank you!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-30-2023 11:44 PM
Hi @Alejandro Martinez
Hope all is well!
Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Announcements





{kind=link}
{kind=link}
{kind=link}
Related Content
- Best AI Note-Taking Apps for iPad in 2026: Features, Use Cases, and Recommendations in Generative AI
- Intialization stage is taking time in lakehouse pipeline in Data Engineering
- SQL Warehouse stuck on "Cluster Start-up Delayed in Data Engineering
- Renaming a folder in adls is taking a lot of time in Data Engineering
- Genie Code inline execution is very slow in Generative AI