Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Apply change data with delete and schema evolution
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Apply change data with delete and schema evolution
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-28-2022 04:56 AM
Hi,
Currently, I'm using structure streaming to insert/update/delete to a table. A row will be deleted if value in 'Operation' column is 'deleted'. Everything seems to work fine until there's a new column.
Since I don't need 'Operation' column in the target table, I use whenMatchedUpdate(set=
..) and whenNotMatchedInsert(values=..) instead of whenMatchedUpdateAll() and whenNotMatchedInsertAll(). However, from the document, it seems the schema evolution occurs only when there is either an updateAll or an insertAll or both. The 'Operation' column also can't be dropped since it's needed in merge (delete) condition.
Is there any way to automatically add a new column and also drop some columns before merging?
Labels:


4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-29-2022 04:16 AM
To help it in that case, I think I would need to see more data + sample data.
You can also implement live delta tables - there are new function apply_changes which can be excellent in your case https://docs.databricks.com/data-engineering/delta-live-tables/delta-live-tables-cdc.html
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-31-2022 08:10 PM
Thank you for your answer. I haven't tried delta live table yet, but it's on the future plan.
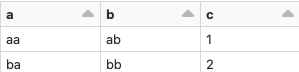
Anyway, the sample data looks something like:
bronze table


Then, the schema of the bronze table automatically got updated with a new column


Currently, I have to manually update the schema of the silver table.
If I use whenMatchedUpdateAll() and whenNotMatchedInsertAll(), the Op column will be added to the silver table.
If I use whenMatchedUpdate() and whenNotMatchedInsert(), the column a1 won't be added to the table.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-01-2022 12:33 AM
please go through this documentation https://docs.delta.io/latest/api/python/index.html
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-01-2022 01:41 AM
Thank you for the document. It's very helpful.
From the doc, I thought I would be able to use
deltaTable = DeltaTable.replace(sparkSession)
.tableName("testTable")
.addColumns(df.schema)
.execute()to update the schema in the code when some schema change is detected.
Anyway, this piece of code does replace the table, so not only the data got update, but all the data are also gone.
Do you have any other suggestion?
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Best practice to log Autoloader UNKNOWN_FIELD_EXCEPTION in Data Engineering
- The Real Problem with AI is Not Intelligence. It is Context. in Generative AI
- Ingestion Gateway DDL Objects Missing - Lakeflow Connect in Data Engineering
- Auto Loader with ignoreMissingFiles and useManagedFileEvents fails on Classic Compute in Data Engineering
- Autoloader inserts null rows in delta table while reading json file in Data Engineering