Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Autoloader directory listing not listing all files
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2023 05:14 AM
Hi community
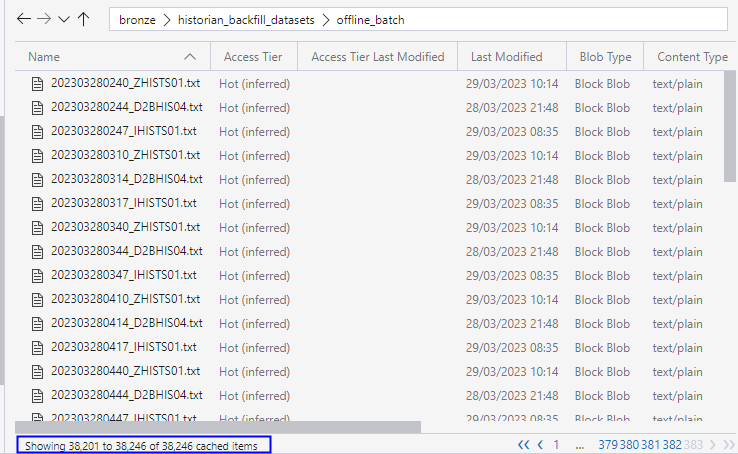
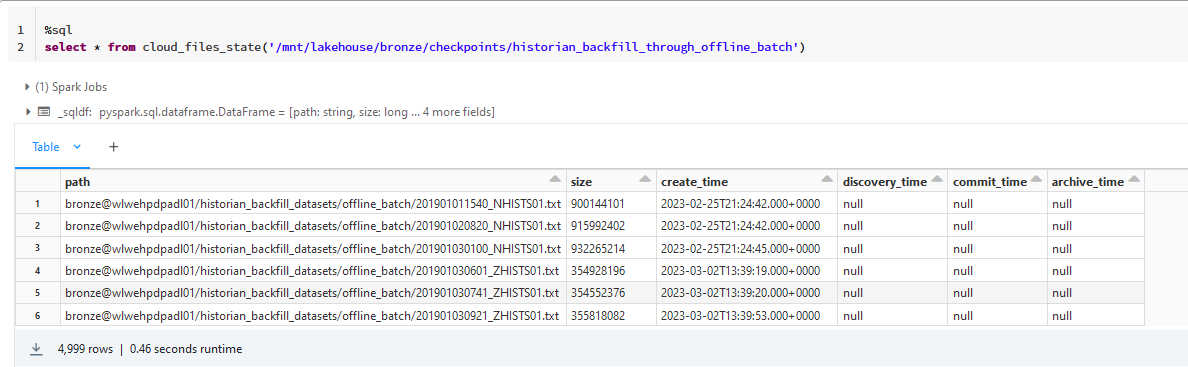
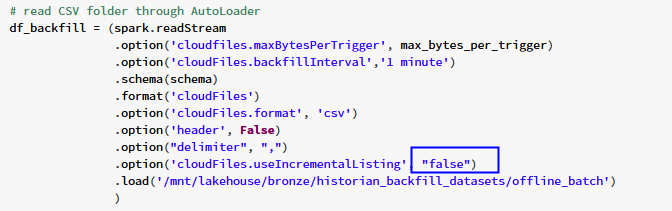
I have an Autoloader pipeline running with following configuration. Unfortunately, it does not detect all files. (see below query definition).


The folder that needs to be read has 38.246 files that all have the same schema and structure.:


Labels:
- Labels:
-
Autoloader


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2023 10:42 AM
Hi @Fabrice Deseyn , My understanding is that this could be because Autoloader returns a fixed no. of results per API call as explained here: https://docs.databricks.com/ingestion/auto-loader/directory-listing-mode.html#how-does-directory-lis...
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2023 05:47 AM
@Fabrice Deseyn
It looks like your storage is not prepared for incremental listing. Use normal Directory Listing to get all of the files.
https://docs.databricks.com/ingestion/auto-loader/directory-listing-mode.html#date-partitioned-files
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2023 06:19 AM
@Daniel Sahal
Thanks, apparently I looked over the useIncrementalListing setting... big mistake from my side...
Thanks for the second pair of eyes!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2023 06:45 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-29-2023 10:42 AM
Hi @Fabrice Deseyn , My understanding is that this could be because Autoloader returns a fixed no. of results per API call as explained here: https://docs.databricks.com/ingestion/auto-loader/directory-listing-mode.html#how-does-directory-lis...
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-30-2023 12:39 AM
Hi @Fabrice Deseyn
Thank you for posting your question in our community! We are happy to assist you.
To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your question?
This will also help other community members who may have similar questions in the future. Thank you for your participation and let us know if you need any further assistance!
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Clarification on Auto Loader Managed File Events with Unity Catalog Managed Volumes in Data Engineering
- Clarification on Auto Loader Managed File Events with Unity Catalog Managed Volumes in Administration & Architecture
- Auto Loader on UC Volumes stopped resolving wildcards in Data Engineering
- Databricks autoloader with manual file delete? in Data Governance
- DeltaFileOperations: Listing improvement? in Data Engineering