Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- com.databricks.sql.io.FileReadException: Error whi...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
com.databricks.sql.io.FileReadException: Error while reading file dbfs:
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-01-2020 10:08 PM
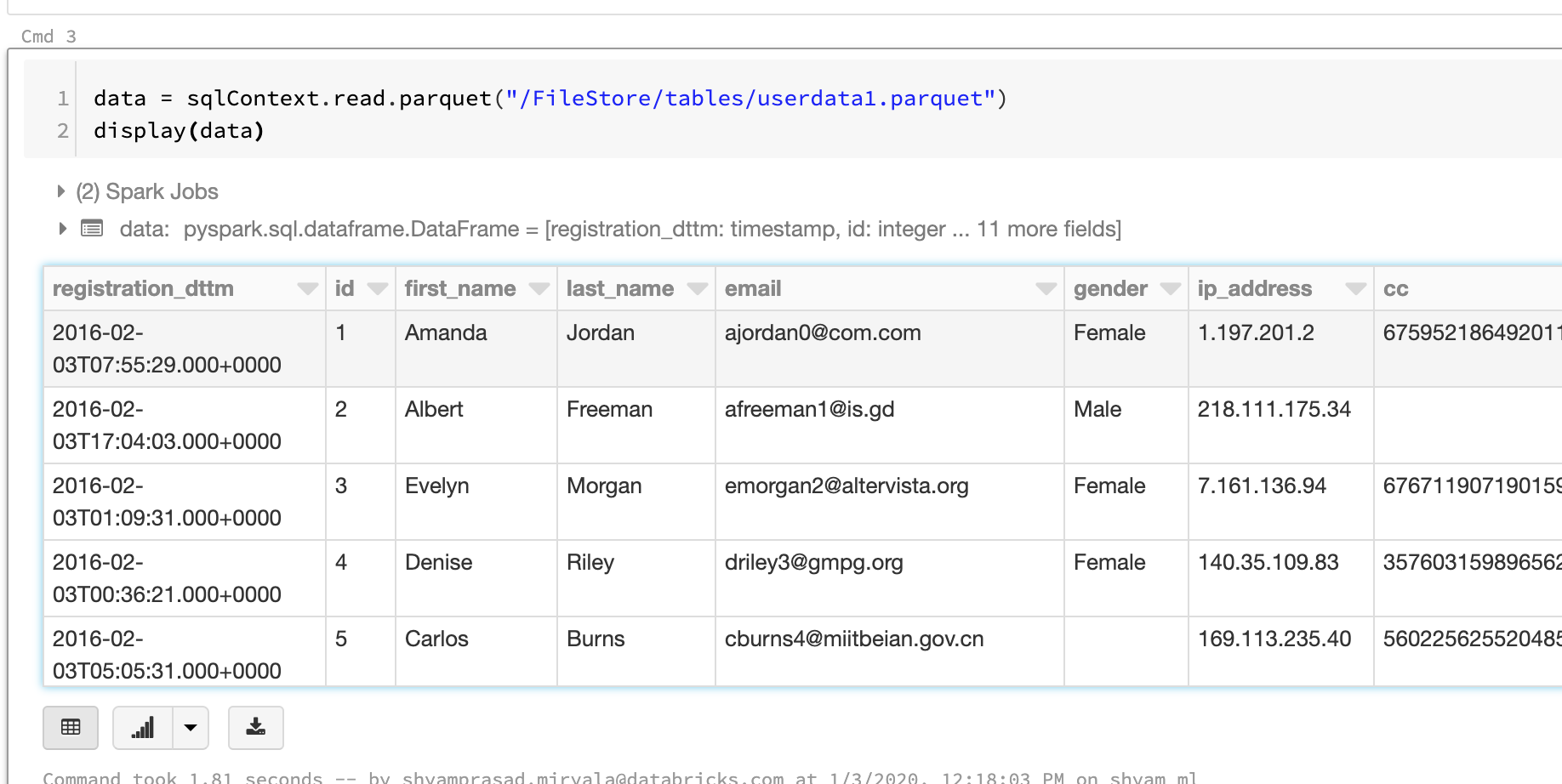
I ran the below statement and got the error
%python
data = sqlContext.read.parquet("/FileStore/tables/ganesh.parquet")
display(data)
Error:
SparkException: Job aborted due to stage failure: Task 0 in stage 27.0 failed 1 times, most recent failure: Lost task 0.0 in stage 27.0 (TID 36, localhost, executor driver): com.databricks.sql.io.FileReadException: Error while reading file dbfs:/FileStore/tables/ganesh.parquet. at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.logFileNameAndThrow(FileScanRDD.scala:331) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.getNext(FileScanRDD.scala:310) at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anonfun$prepareNextFile$1.apply(FileScanRDD.scala:463) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anonfun$prepareNextFile$1.apply(FileScanRDD.scala:451) at scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24) at scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24) at org.apache.spark.util.threads.SparkThreadLocalCapturingRunnable$$anonfun$run$1.apply$mcV$sp(SparkThreadLocalForwardingThreadPoolExecutor.scala:100) at org.apache.spark.util.threads.SparkThreadLocalCapturingRunnable$$anonfun$run$1.apply(SparkThreadLocalForwardingThreadPoolExecutor.scala:100) at org.apache.spark.util.threads.SparkThreadLocalCapturingRunnable$$anonfun$run$1.apply(SparkThreadLocalForwardingThreadPoolExecutor.scala:100) at org.apache.spark.util.threads.SparkThreadLocalCapturingHelper$class.runWithCaptured(SparkThreadLocalForwardingThreadPoolExecutor.scala:68) at org.apache.spark.util.threads.SparkThreadLocalCapturingRunnable.runWithCaptured(SparkThreadLocalForwardingThreadPoolExecutor.scala:97) at org.apache.spark.util.threads.SparkThreadLocalCapturingRunnable.run(SparkThreadLocalForwardingThreadPoolExecutor.scala:100) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.lang.RuntimeException: unexpected number of values encountered in Parquet batch, expected = 2 returned = 1 at com.databricks.sql.io.parquet.VectorizedColumnReader.readBatch(VectorizedColumnReader.java:368) at com.databricks.sql.io.parquet.DatabricksVectorizedParquetRecordReader.nextBatch(DatabricksVectorizedParquetRecordReader.java:346) at org.apache.spark.sql.execution.datasources.parquet.VectorizedParquetRecordReader.nextKeyValue(VectorizedParquetRecordReader.java:159) at org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:40) at org.apache.spark.sql.execution.datasources.FileScanRDD$$anon$1$$anon$2.getNext(FileScanRDD.scala:283) ... 14 more
Labels:
- Labels:
-
Dbfs - databricks file system
-
Python3


5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2020 11:00 PM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2020 09:16 PM
@shyamspr
Thanks for your response. The file has only 1 row of data and I'm using the community edition of databricks. Also please see attached the parquet file that was generated. Please note that I used Parquet.Net (.Net Library for generating parquet File) Nuget Package to generate Parquet File. Also I uploaded the parquet file manually to DBFS. Is there any way I can upload the parquet file so you can validate and let me know where the issue is?
var itemIDColumn = new Parquet.Data.DataColumn(new DataField<string>("ItemID"), new string[] { consumersRatingInfo.ItemID }); var retailerIDColumn = new Parquet.Data.DataColumn(new DataField<string>("RetailerID"), new string[] { consumersRatingInfo.RetailerID });
//var ratingDateTimeColumn = new Parquet.Data.DataColumn(new DateTimeDataField<DateTime>("RatingDateTime"), new DateTime[] { consumersRatingInfo.RatingDateTime });
//var ratingDateTimeColumn = new Parquet.Data.DataColumn(new DateTimeDataField("dateDateAndTime", DateTimeFormat.DateAndTime), new DateTimeOffset[] { consumersRatingInfo.RatingDateTime });
var ratingValueColumn = new Parquet.Data.DataColumn(new DataField<int>("RatingValue"), new int[] { consumersRatingInfo.RatingValue });
var itemUPCColumn = new Parquet.Data.DataColumn(new DataField<string>("ItemUPC"), new string[] { consumersRatingInfo.ItemUPC });
var greceiptIDColumn = new Parquet.Data.DataColumn(new DataField<string>("GReceiptID"), new string[] { consumersRatingInfo.GReceiptID });
var itemNameColumn = new Parquet.Data.DataColumn(new DataField<string>("ItemName"), new string[] { consumersRatingInfo.ItemName });
var ratingLabelColumn = new Parquet.Data.DataColumn(new DataField<string>("RatingLabel"), new string[] { consumersRatingInfo.RatingLabel });
var retailerTypeColumn = new Parquet.Data.DataColumn(new DataField<string>("RetailerType"), new string[] { consumersRatingInfo.RetailerType });
//var ratingColumn = new Parquet.Data.DataColumn(new DataField<List<ConsumersRatingAttributesInfo>>("Rating"), new List<ConsumersRatingAttributesInfo>[] { consumersRatingAttributesInfos });
// create file schema
var schema = new Schema(idColumn.Field, cityColumn.Field, itemIDColumn.Field, retailerIDColumn.Field, ratingValueColumn.Field, itemUPCColumn.Field, greceiptIDColumn.Field, itemNameColumn.Field, ratingLabelColumn.Field, retailerTypeColumn.Field);
using (Stream fileStream = System.IO.File.OpenWrite("c:\\Work\\ganesh.parquet"))
{
using (var parquetWriter = new ParquetWriter(schema, fileStream))
{
// create a new row group in the file
using (ParquetRowGroupWriter groupWriter = parquetWriter.CreateRowGroup())
{
groupWriter.WriteColumn(idColumn);
groupWriter.WriteColumn(cityColumn);
groupWriter.WriteColumn(itemIDColumn);
groupWriter.WriteColumn(retailerIDColumn);
// groupWriter.WriteColumn(ratingDateTimeColumn);
groupWriter.WriteColumn(ratingValueColumn);
groupWriter.WriteColumn(itemUPCColumn);
groupWriter.WriteColumn(greceiptIDColumn);
groupWriter.WriteColumn(itemNameColumn);
groupWriter.WriteColumn(ratingLabelColumn);
groupWriter.WriteColumn(retailerTypeColumn);
}
}
}
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-05-2020 10:23 AM
@shyamspr - Please respond
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-19-2020 12:41 PM
I'm having a similar issue reading a JSON file. It is ~550MB compressed and is on a single line:
val cfilename = "c_datafeed_20200128.json.gz"
val events = spark.read.json(s"/mnt/c/input1/$cfilename")
display(events)
The filename is correct and the file is all a single line of JSON starting with [{" and ending with "}]. It is over 4GB decompressed. I'm using a Standard_DS4_v2 (28.0 GB Memory, 8 Cores, 1.5 DBU)
20/02/19 20:32:34 ERROR FileScanRDD: Error while reading file dbfs:/mnt/c/input1/c_datafeed_20200128.json.gz.
20/02/19 20:32:34 ERROR Executor: Exception in task 0.0 in stage 1.0 (TID 16)
com.databricks.sql.io.FileReadException: Error while reading file
Error while reading file dbfs:/mnt/c/input1/c_datafeed_20200128.json.gz.
at org.apache.spark.sql.execution.datasources.FileScanRDD$anon$1$anon$2.logFileNameAndThrow(FileScanRDD.scala:331)
at org.apache.spark.sql.execution.datasources.FileScanRDD$anon$1$anon$2.getNext(FileScanRDD.scala:310)
at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73)
at org.apache.spark.sql.execution.datasources.FileScanRDD$anon$1.nextIterator(FileScanRDD.scala:397)
at org.apache.spark.sql.execution.datasources.FileScanRDD$anon$1.hasNext(FileScanRDD.scala:250)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$anonfun$13$anon$1.hasNext(WholeStageCodegenExec.scala:640)
at scala.collection.Iterator$anon$12.hasNext(Iterator.scala:440)
at scala.collection.Iterator$class.isEmpty(Iterator.scala:331)
at scala.collection.AbstractIterator.isEmpty(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.reduceLeftOption(TraversableOnce.scala:203)
at scala.collection.AbstractIterator.reduceLeftOption(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.reduceOption(TraversableOnce.scala:210)
at scala.collection.AbstractIterator.reduceOption(Iterator.scala:1334)
at org.apache.spark.sql.catalyst.json.JsonInferSchema$anonfun$1.apply(JsonInferSchema.scala:70)
at org.apache.spark.sql.catalyst.json.JsonInferSchema$anonfun$1.apply(JsonInferSchema.scala:50)
at org.apache.spark.rdd.RDD$anonfun$mapPartitions$1$anonfun$apply$23.apply(RDD.scala:830)
at org.apache.spark.rdd.RDD$anonfun$mapPartitions$1$anonfun$apply$23.apply(RDD.scala:830)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:60)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:353)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:317)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.doRunTask(Task.scala:140)
at org.apache.spark.scheduler.Task.run(Task.scala:113)
at org.apache.spark.executor.Executor$TaskRunner$anonfun$13.apply(Executor.scala:533)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1541)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:539)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.OutOfMemoryError: Requested array size exceeds VM limit
at java.util.Arrays.copyOf(Arrays.java:3236)
at org.apache.hadoop.io.Text.setCapacity(Text.java:266)
at org.apache.hadoop.io.Text.append(Text.java:236)
at org.apache.hadoop.util.LineReader.readDefaultLine(LineReader.java:243)
at org.apache.hadoop.util.LineReader.readLine(LineReader.java:174)
at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.skipUtfByteOrderMark(LineRecordReader.java:144)
at org.apache.hadoop.mapreduce.lib.input.LineRecordReader.nextKeyValue(LineRecordReader.java:184)
at org.apache.spark.sql.execution.datasources.RecordReaderIterator.hasNext(RecordReaderIterator.scala:40)
at org.apache.spark.sql.execution.datasources.HadoopFileLinesReader.hasNext(HadoopFileLinesReader.scala:69)
at scala.collection.Iterator$anon$11.hasNext(Iterator.scala:409)
at scala.collection.Iterator$anon$11.hasNext(Iterator.scala:409)
at org.apache.spark.sql.execution.datasources.FileScanRDD$anon$1$anon$2.getNext(FileScanRDD.scala:283)
at org.apache.spark.util.NextIterator.hasNext(NextIterator.scala:73)
at org.apache.spark.sql.execution.datasources.FileScanRDD$anon$1.nextIterator(FileScanRDD.scala:397)
at org.apache.spark.sql.execution.datasources.FileScanRDD$anon$1.hasNext(FileScanRDD.scala:250)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIteratorForCodegenStage1.processNext(Unknown Source)
at org.apache.spark.sql.execution.BufferedRowIterator.hasNext(BufferedRowIterator.java:43)
at org.apache.spark.sql.execution.WholeStageCodegenExec$anonfun$13$anon$1.hasNext(WholeStageCodegenExec.scala:640)
at scala.collection.Iterator$anon$12.hasNext(Iterator.scala:440)
at scala.collection.Iterator$class.isEmpty(Iterator.scala:331)
at scala.collection.AbstractIterator.isEmpty(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.reduceLeftOption(TraversableOnce.scala:203)
at scala.collection.AbstractIterator.reduceLeftOption(Iterator.scala:1334)
at scala.collection.TraversableOnce$class.reduceOption(TraversableOnce.scala:210)
at scala.collection.AbstractIterator.reduceOption(Iterator.scala:1334)
at org.apache.spark.sql.catalyst.json.JsonInferSchema$anonfun$1.apply(JsonInferSchema.scala:70)
at org.apache.spark.sql.catalyst.json.JsonInferSchema$anonfun$1.apply(JsonInferSchema.scala:50)
at org.apache.spark.rdd.RDD$anonfun$mapPartitions$1$anonfun$apply$23.apply(RDD.scala:830)
at org.apache.spark.rdd.RDD$anonfun$mapPartitions$1$anonfun$apply$23.apply(RDD.scala:830)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:60)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:353)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:317)Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-20-2020 12:04 PM
I resolved this issue by increasing my cluster and worker size. I also added .option("multiline", "true") to the spark.read.json command. This seemed counter intuitive as the JSON was all on one line but it worked.
Announcements





{kind=link}
Related Content
- sdp-meta (dlt-meta) vs lakeflow_framework: when should we use which? in Data Engineering
- credential delegation not found (404) / permission delegation name (500) in Generative AI
- Getting 'Unauthorized Access' when Serverless compute is trying to read s3 bucket data in Data Engineering
- DLT pipelines failing out of memory (serverless) in Data Engineering
- Auto CDC Delete Propagation Issue: Streaming CDF Reads Don't Capture Delete Events from Auto CDC in Data Engineering