Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- commit time is coming as null in autoloader
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-19-2025 12:09 AM
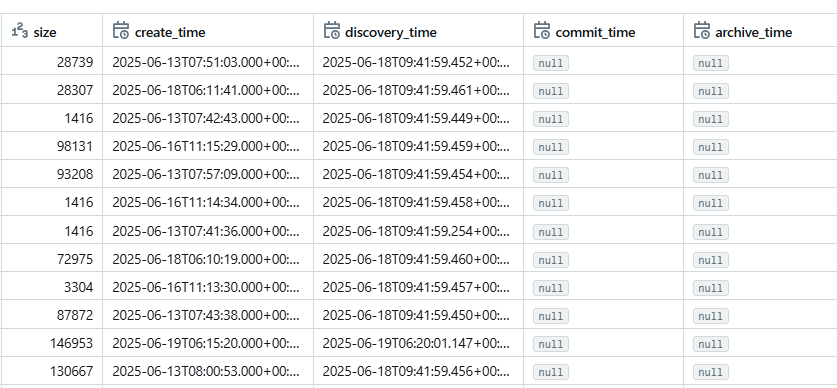
As per the databricks new feature in autoloader that we can use archival and move feature in autoloader however I am trying to use that feature using databricks 16.4.x.scala2.12 however commit time is still coming null as its mentioned in the documentation if commit time is null this feature won't work . how can I resolve it?
I am using below autoloader configuration:
df=spark.readStream.format("cloudfiles")\
.option("cloudfiles.format","json")\
.option("cloudfiles.schemaLocation",checkpoint_path)\
.option("multiLine", "True")\
.option("cloudFiles.backfillInterval","10 minutes")\
.option("cloudFiles.inferColumnTypes", "True")\
.load(ingestDirectory)
dfOutput = (
df.writeStream
.trigger(once=True)
.format("delta")
.option("mergeSchema", "true")
.option("checkpointLocation",checkpoint_path)
.start(CuratedDirectory)
)
dfOutput.awaitTermination()


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2025 09:49 PM
@shrutikatyal I believe the commit_time only functions when the cloudFiles.cleanSource option is enabled. I don't see this option present in your snippet. Could you please enable this option for the read and check?
Refer to the below documentation, which specifies that column commit_time is supported in Databricks Runtime 16.4 and above when cloudFiles.cleanSource is enabled
https://docs.databricks.com/aws/en/sql/language-manual/functions/cloud_files_state
A file might be processed but marked as committed arbitrarily later. commit_time is updated usually at the start of the next microbatch.
9 REPLIES 9
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-19-2025 10:10 AM
You're right — the new **archival and move feature in Auto Loader** depends on the `_commit_timestamp` column. If that value is coming as `null`, the feature won't work, as mentioned in the documentation.
To fix this, you need to make sure you're explicitly enabling the `commitTime` metadata column using the following option in your Auto Loader configuration:
```python
.option("cloudFiles.addColumns", "commitTime")
```
This ensures that the `_commit_timestamp` field gets populated during ingestion.
Here’s the corrected version of your code:
```python
df = (
spark.readStream.format("cloudfiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.schemaLocation", checkpoint_path)
.option("multiLine", "true")
.option("cloudFiles.backfillInterval", "10 minutes")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.addColumns", "commitTime") # Required to get _commit_timestamp
.load(ingestDirectory)
)
```
Once this is set, `_commit_timestamp` should be populated properly, and the archival/move feature should start working as expected.
Yogesh Verma
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2025 12:48 AM
hi Yogesh,
I am getting below error if I am trying to add this in my autoloader configuration i.e. option ("cloudFiles.addColumns", "commitTime").
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2025 12:52 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2025 12:54 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-21-2025 09:49 PM
@shrutikatyal I believe the commit_time only functions when the cloudFiles.cleanSource option is enabled. I don't see this option present in your snippet. Could you please enable this option for the read and check?
Refer to the below documentation, which specifies that column commit_time is supported in Databricks Runtime 16.4 and above when cloudFiles.cleanSource is enabled
https://docs.databricks.com/aws/en/sql/language-manual/functions/cloud_files_state
A file might be processed but marked as committed arbitrarily later. commit_time is updated usually at the start of the next microbatch.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-22-2025 11:25 PM
Thanks, its working now
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-02-2025 05:31 AM
hi,
I am interested in data bricks certified associate data Engineer certification can I get any voucher?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-02-2025 05:46 AM
Hey @shrutikatyal
I believe the only current route to get a discount voucher would be the following:
https://community.databricks.com/t5/events/dais-2025-virtual-learning-festival-11-june-02-july-2025/...
I think it’s the last day of the event so you might need to be quick!
hope this helps,
TheOC
Cheers,
TheOC
TheOC
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-13-2025 08:54 PM
hi,
I have done the certification using data bricks learning festival however I haven't got any voucher yet.
Thanks
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Databricks autoloader with manual file delete? in Data Governance
- Broken s3 file paths in File Notifications for auto loader in Data Engineering
- Autoloader with availableNow=True and overwrite mode removes data in second micro-batch (DBR 16.3) in Data Engineering
- Delta Live Table - Delta Table Sink Error after the first run in Data Engineering