Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: DLT AutoLoader S3 Access Denied Using File Not...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-06-2023 12:45 PM
Hi all,
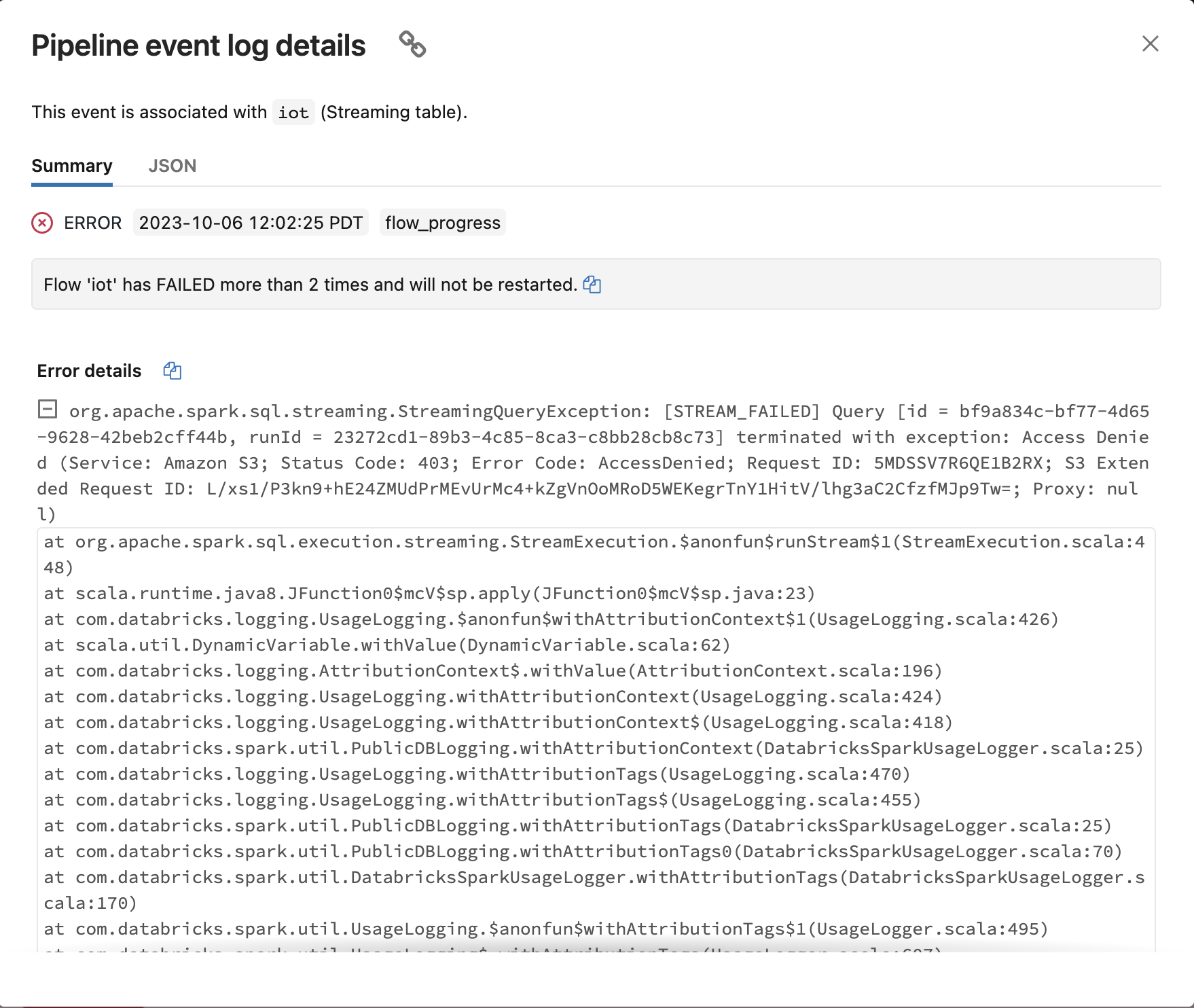
I'm attempting to switch our DLT pipeline using Auto Loader from Directory Listing to File Notification mode, and running in to S3 Access Denied issues with very little detail. I have followed all the instructions here and here to set up File Notification permissions and an Instance Profile with access to the S3 bucket, yet I still get Access Denied on S3 which trying to start the DLT pipeline. The error screenshot is attached below as well as a full stack trace here:
org.apache.spark.sql.streaming.StreamingQueryException: [STREAM_FAILED] Query [id = bf9a834c-bf77-4d65-9628-42beb2cff44b, runId = 23272cd1-89b3-4c85-8ca3-c8bb28cb8c73] terminated with exception: Access Denied (Service: Amazon S3; Status Code: 403; Error Code: AccessDenied; Request ID: 5MDSSV7R6QE1B2RX; S3 Extended Request ID: L/xs1/P3kn9+hE24ZMUdPrMEvUrMc4+kZgVnOoMRoD5WEKegrTnY1HitV/lhg3aC2CfzfMJp9Tw=; Proxy: null)
at org.apache.spark.sql.execution.streaming.StreamExecution.$anonfun$runStream$1(StreamExecution.scala:448)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.logging.UsageLogging.$anonfun$withAttributionContext$1(UsageLogging.scala:426)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at com.databricks.logging.AttributionContext$.withValue(AttributionContext.scala:196)
at com.databricks.logging.UsageLogging.withAttributionContext(UsageLogging.scala:424)
at com.databricks.logging.UsageLogging.withAttributionContext$(UsageLogging.scala:418)
at com.databricks.spark.util.PublicDBLogging.withAttributionContext(DatabricksSparkUsageLogger.scala:25)
at com.databricks.logging.UsageLogging.withAttributionTags(UsageLogging.scala:470)
at com.databricks.logging.UsageLogging.withAttributionTags$(UsageLogging.scala:455)
at com.databricks.spark.util.PublicDBLogging.withAttributionTags(DatabricksSparkUsageLogger.scala:25)
at com.databricks.spark.util.PublicDBLogging.withAttributionTags0(DatabricksSparkUsageLogger.scala:70)
at com.databricks.spark.util.DatabricksSparkUsageLogger.withAttributionTags(DatabricksSparkUsageLogger.scala:170)
at com.databricks.spark.util.UsageLogging.$anonfun$withAttributionTags$1(UsageLogger.scala:495)
at com.databricks.spark.util.UsageLogging$.withAttributionTags(UsageLogger.scala:607)
at com.databricks.spark.util.UsageLogging$.withAttributionTags(UsageLogger.scala:616)
at com.databricks.spark.util.UsageLogging.withAttributionTags(UsageLogger.scala:495)
at com.databricks.spark.util.UsageLogging.withAttributionTags$(UsageLogger.scala:493)
at org.apache.spark.sql.execution.streaming.StreamExecution.withAttributionTags(StreamExecution.scala:82)
at org.apache.spark.sql.execution.streaming.StreamExecution.org$apache$spark$sql$execution$streaming$StreamExecution$$runStream(StreamExecution.scala:354)
at org.apache.spark.sql.execution.streaming.StreamExecution$$anon$1.$anonfun$run$2(StreamExecution.scala:276)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.unity.UCSEphemeralState$Handle.runWith(UCSEphemeralState.scala:41)
at com.databricks.unity.HandleImpl.runWith(UCSHandle.scala:99)
at com.databricks.unity.HandleImpl.$anonfun$runWithAndClose$1(UCSHandle.scala:104)
at scala.util.Using$.resource(Using.scala:269)
at com.databricks.unity.HandleImpl.runWithAndClose(UCSHandle.scala:103)
at org.apache.spark.sql.execution.streaming.StreamExecution$$anon$1.run(StreamExecution.scala:276)
com.amazonaws.services.s3.model.AmazonS3Exception: Access Denied (Service: Amazon S3; Status Code: 403; Error Code: AccessDenied; Request ID: 5MDSSV7R6QE1B2RX; S3 Extended Request ID: L/xs1/P3kn9+hE24ZMUdPrMEvUrMc4+kZgVnOoMRoD5WEKegrTnY1HitV/lhg3aC2CfzfMJp9Tw=; Proxy: null)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleErrorResponse(AmazonHttpClient.java:1879)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.handleServiceErrorResponse(AmazonHttpClient.java:1418)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeOneRequest(AmazonHttpClient.java:1387)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeHelper(AmazonHttpClient.java:1157)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.doExecute(AmazonHttpClient.java:814)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.executeWithTimer(AmazonHttpClient.java:781)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.execute(AmazonHttpClient.java:755)
at com.amazonaws.http.AmazonHttpClient$RequestExecutor.access$500(AmazonHttpClient.java:715)
at com.amazonaws.http.AmazonHttpClient$RequestExecutionBuilderImpl.execute(AmazonHttpClient.java:697)
at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:561)
at com.amazonaws.http.AmazonHttpClient.execute(AmazonHttpClient.java:541)
at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5456)
at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5403)
at com.amazonaws.services.s3.AmazonS3Client.invoke(AmazonS3Client.java:5397)
at com.amazonaws.services.s3.AmazonS3Client.getBucketNotificationConfiguration(AmazonS3Client.java:2843)
at com.amazonaws.services.s3.AmazonS3Client.getBucketNotificationConfiguration(AmazonS3Client.java:2826)
at com.databricks.sql.sqs.autoIngest.S3EventNotificationSetup.$anonfun$setUpS3EventNotification$1(S3EventNotificationSetup.scala:181)
at com.databricks.sql.sqs.autoIngest.S3EventNotificationSetup$.withRetries(S3EventNotificationSetup.scala:642)
at com.databricks.sql.sqs.autoIngest.S3EventNotificationSetup.setUpS3EventNotification(S3EventNotificationSetup.scala:180)
at com.databricks.sql.sqs.autoIngest.S3EventNotificationSetup.<init>(S3EventNotificationSetup.scala:144)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(NativeConstructorAccessorImpl.java:-2)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at com.databricks.sql.fileNotification.autoIngest.EventNotificationSetup$.$anonfun$create$1(EventNotificationSetup.scala:59)
at com.databricks.sql.fileNotification.autoIngest.ResourceManagementUtils$.unwrapInvocationTargetException(ResourceManagementUtils.scala:42)
at com.databricks.sql.fileNotification.autoIngest.EventNotificationSetup$.create(EventNotificationSetup.scala:50)
at com.databricks.sql.fileNotification.autoIngest.CloudFilesSourceProvider.$anonfun$createSource$1(CloudFilesSourceProvider.scala:124)
at scala.Option.getOrElse(Option.scala:189)
at com.databricks.sql.fileNotification.autoIngest.CloudFilesSourceProvider.createSource(CloudFilesSourceProvider.scala:109)
at org.apache.spark.sql.execution.datasources.DataSource.createSource(DataSource.scala:322)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$1.$anonfun$applyOrElse$1(MicroBatchExecution.scala:183)
at scala.collection.mutable.HashMap.getOrElseUpdate(HashMap.scala:86)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$1.applyOrElse(MicroBatchExecution.scala:180)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution$$anonfun$1.applyOrElse(MicroBatchExecution.scala:178)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:465)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(origin.scala:69)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:465)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:316)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:312)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1269)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1268)
at org.apache.spark.sql.catalyst.plans.logical.Filter.mapChildren(basicLogicalOperators.scala:325)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:316)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:312)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1269)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1268)
at org.apache.spark.sql.catalyst.plans.logical.Project.mapChildren(basicLogicalOperators.scala:83)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:316)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:312)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1269)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1268)
at org.apache.spark.sql.catalyst.plans.logical.Project.mapChildren(basicLogicalOperators.scala:83)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:316)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:312)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1269)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1268)
at org.apache.spark.sql.catalyst.plans.logical.Project.mapChildren(basicLogicalOperators.scala:83)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:316)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:312)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1269)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1268)
at org.apache.spark.sql.catalyst.plans.logical.Project.mapChildren(basicLogicalOperators.scala:83)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:316)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:312)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$3(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren(TreeNode.scala:1269)
at org.apache.spark.sql.catalyst.trees.UnaryLike.mapChildren$(TreeNode.scala:1268)
at org.apache.spark.sql.catalyst.plans.logical.CollectMetrics.mapChildren(basicLogicalOperators.scala:2199)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:470)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:316)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:312)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:33)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:441)
at org.apache.spark.sql.catalyst.trees.TreeNode.transform(TreeNode.scala:409)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.planQuery(MicroBatchExecution.scala:178)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.logicalPlan$lzycompute(MicroBatchExecution.scala:340)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.logicalPlan(MicroBatchExecution.scala:340)
at org.apache.spark.sql.execution.streaming.MicroBatchExecution.initSources(MicroBatchExecution.scala:356)
at org.apache.spark.sql.execution.streaming.StreamExecution.$anonfun$runStream$2(StreamExecution.scala:403)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:1113)
at org.apache.spark.sql.execution.streaming.StreamExecution.$anonfun$runStream$1(StreamExecution.scala:372)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.logging.UsageLogging.$anonfun$withAttributionContext$1(UsageLogging.scala:426)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at com.databricks.logging.AttributionContext$.withValue(AttributionContext.scala:196)
at com.databricks.logging.UsageLogging.withAttributionContext(UsageLogging.scala:424)
at com.databricks.logging.UsageLogging.withAttributionContext$(UsageLogging.scala:418)
at com.databricks.spark.util.PublicDBLogging.withAttributionContext(DatabricksSparkUsageLogger.scala:25)
at com.databricks.logging.UsageLogging.withAttributionTags(UsageLogging.scala:470)
at com.databricks.logging.UsageLogging.withAttributionTags$(UsageLogging.scala:455)
at com.databricks.spark.util.PublicDBLogging.withAttributionTags(DatabricksSparkUsageLogger.scala:25)
at com.databricks.spark.util.PublicDBLogging.withAttributionTags0(DatabricksSparkUsageLogger.scala:70)
at com.databricks.spark.util.DatabricksSparkUsageLogger.withAttributionTags(DatabricksSparkUsageLogger.scala:170)
at com.databricks.spark.util.UsageLogging.$anonfun$withAttributionTags$1(UsageLogger.scala:495)
at com.databricks.spark.util.UsageLogging$.withAttributionTags(UsageLogger.scala:607)
at com.databricks.spark.util.UsageLogging$.withAttributionTags(UsageLogger.scala:616)
at com.databricks.spark.util.UsageLogging.withAttributionTags(UsageLogger.scala:495)
at com.databricks.spark.util.UsageLogging.withAttributionTags$(UsageLogger.scala:493)
at org.apache.spark.sql.execution.streaming.StreamExecution.withAttributionTags(StreamExecution.scala:82)
at org.apache.spark.sql.execution.streaming.StreamExecution.org$apache$spark$sql$execution$streaming$StreamExecution$$runStream(StreamExecution.scala:354)
at org.apache.spark.sql.execution.streaming.StreamExecution$$anon$1.$anonfun$run$2(StreamExecution.scala:276)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.unity.UCSEphemeralState$Handle.runWith(UCSEphemeralState.scala:41)
at com.databricks.unity.HandleImpl.runWith(UCSHandle.scala:99)
at com.databricks.unity.HandleImpl.$anonfun$runWithAndClose$1(UCSHandle.scala:104)
at scala.util.Using$.resource(Using.scala:269)
at com.databricks.unity.HandleImpl.runWithAndClose(UCSHandle.scala:103)
at org.apache.spark.sql.execution.streaming.StreamExecution$$anon$1.run(StreamExecution.scala:276)
More information:
* The bucket is set up in the Unity Catalog as an External Location already -- does this interfere with Auto Loader File Notification mode?
* The bucket is ingested with Directory Listing mode perfectly fine with a different DLT pipeline
The DLT script source is here:
import dlt
from pyspark.sql.functions import *
from pyspark.sql.types import *
json_schema = StructType(
[
StructField("timestamp", TimestampType(), True),
StructField("name", StringType(), True),
StructField("value", FloatType(), True),
StructField("type", StringType(), True),
StructField("site_id", StringType(), True),
StructField("tenant_id", StringType(), True),
]
)
@dlt.table(
partition_cols=["site_id", "month"],
)
def iot():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.schema(json_schema)
.option("cloudFiles.format", "csv")
.option("cloudFiles.maxFilesPerTrigger", "3000000")
.option("cloudFiles.maxBytesPerTrigger", "3000m")
.option("cloudFiles.useNotifications", "true")
.option("cloudFiles.region", "us-west-2")
.load("s3://csv-data-XXXXXXXXXXX")
.where('timestamp >= "2023-09-20"')
.withColumn("month", concat_ws("-", year("timestamp"), month("timestamp")))
.withColumn("value", col("value").cast("float"))
.withColumn("timestamp", col("timestamp").cast("timestamp"))
.select("site_id", "month", "timestamp", "name", "value")
)
Please let me know if there is anymore information I may provide to help out.
Thanks!
Labels:
- Labels:
-
Workflows


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2023 01:50 PM
Thanks @Retired_mod, we ended up abandoning this route due to limitations imposed by the Shared compute access mode enforced by DLT's, and opted for a standard Spark Structured Streaming Job (using Kafka) in the end.
2 REPLIES 2
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2023 10:03 AM
Below are topic to check:
1. Permissions mentioned here : https://docs.databricks.com/en/ingestion/auto-loader/file-notification-mode.html
2. try using SQS directly instead of letting databricks manage the SQS and SNS resources like below:
Accordingly update the SQS resource policy so that roleArn can read the messages.
.option('cloudFiles.region', 'us-xxx-2')
.option('cloudFiles.queueUrl', 'name-of-queue')
.option('cloudFiles.roleArn', 'ARN of your role')
.option('cloudFiles.roleSessionName','roleSessionName')
.option('cloudFiles.stsEndpoint','endpoint')
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2023 01:50 PM
Thanks @Retired_mod, we ended up abandoning this route due to limitations imposed by the Shared compute access mode enforced by DLT's, and opted for a standard Spark Structured Streaming Job (using Kafka) in the end.
Announcements





{kind=link}
Related Content
- Broken s3 file paths in File Notifications for auto loader in Data Engineering
- Autoloader - File Notification Mode in Data Engineering
- Unable to use Auto Loader for External Location in Community Edition in Data Engineering
- Issue with Databricks Jobs: SQLSTATE: XXKST in Data Engineering
- Autoloader with file notifications on a queue that is on a different storage account to the blobs in Data Engineering