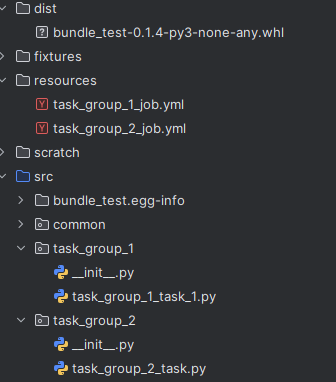
I have a project witch my commons, like sparksession object (to run code in pycharm using databricks connect library and the same code directly on databricks).I have under src a few packages from which DAB creates separate jobs. I'm using PyCharm. Structure of my project is as follows:
src/task_group1/<many_python_tasks>
src/task_group2<many_python_tasks>
resources/task_group1.yml #tasks and job structure
resources/task_group2.yml #tasks and job structure
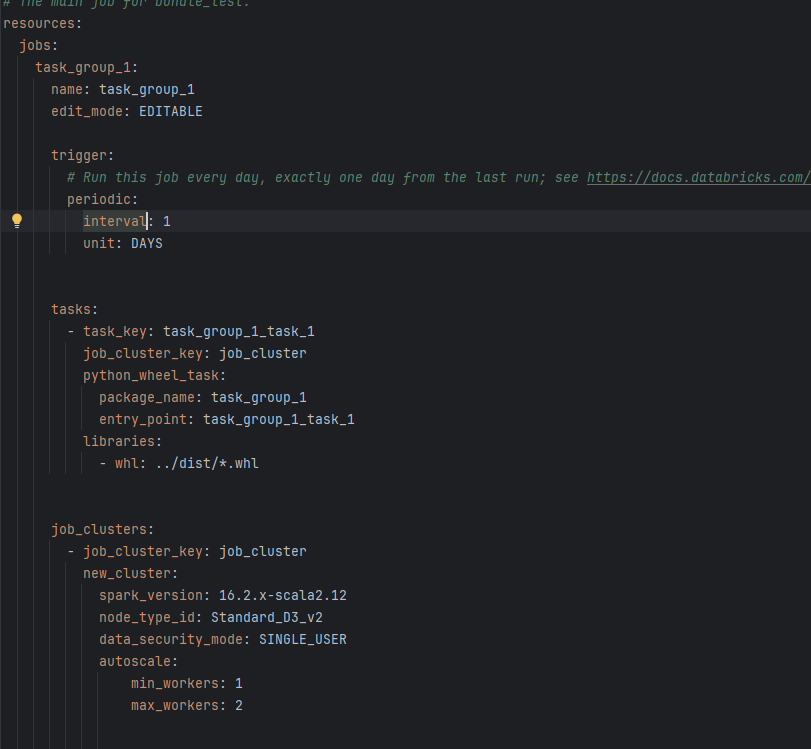
tasks:
- task_key: main_task
job_cluster_key: job_cluster
python_wheel_task:
package_name: task_group1
entry_point: main
libraries:
# By default we just include the .whl file generated for the bundle_test package.
# See https://docs.databricks.com/dev-tools/bundles/library-dependencies.html
# for more information on how to add other libraries.
- whl: ../dist/*.whl
After running on Databricks I have this error: run failed with error message Python wheel with name task_group2 could not be found. Please check the driver logs for more details
Is Databricks Asset Bundles should generate many wheel files? Each *.whl file for each job? One wheel generated by DAB have all packages included. Is it a matter of wrong references in yml files and setup.py?
setup.py with corect entry points.
packages=find_packages(where="./src"),
package_dir={"": "src"},







{kind=link}
{kind=link}
{kind=link}