Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Enable to use library GraphFrames
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-28-2025 08:17 AM
Hello,
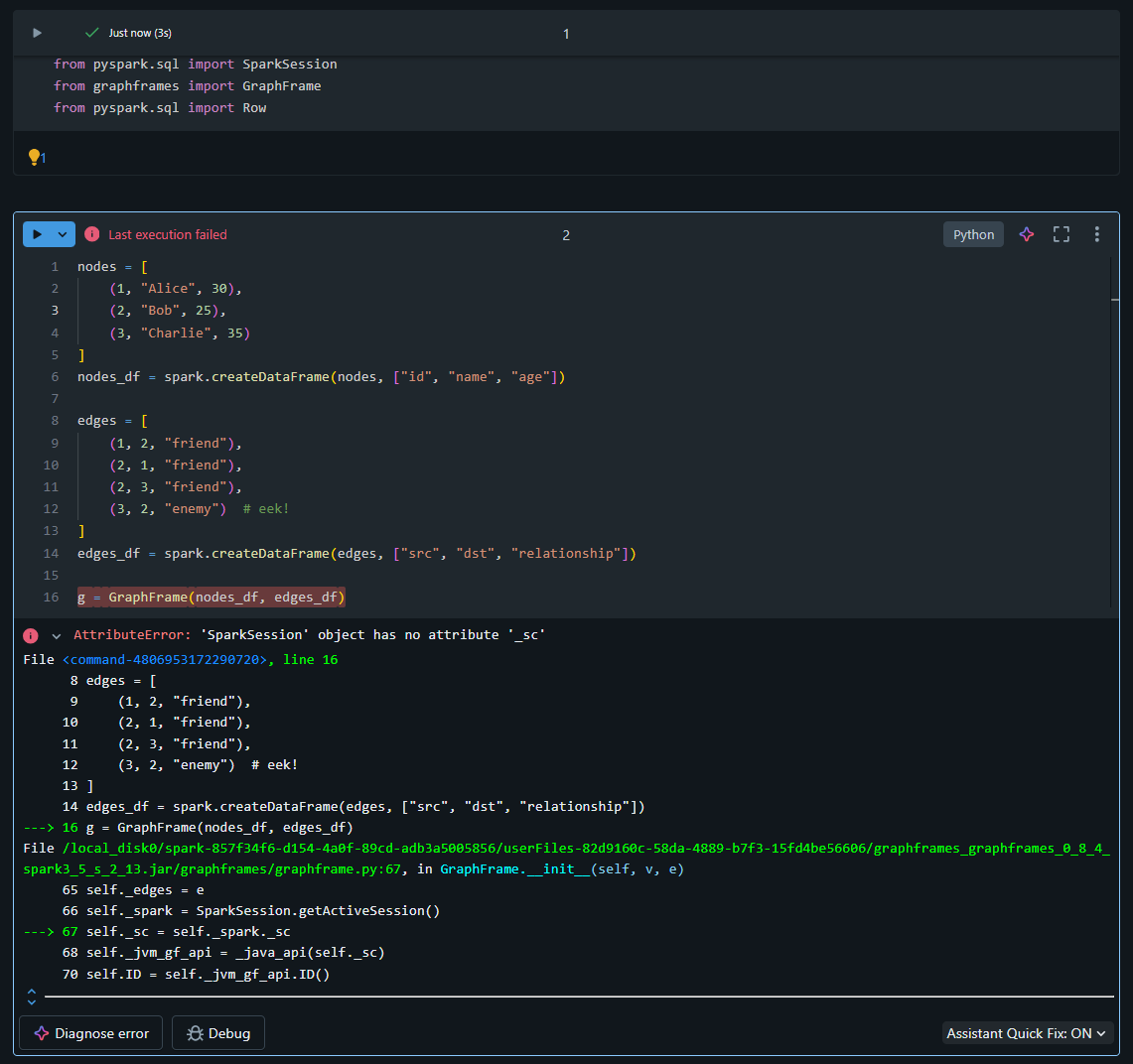
I am trying to install and use the library GraphFrames but keep receiving the following error: "AttributeError: 'SparkSession' object has no attribute '_sc'".
I have tried to install the library on my all-purpose cluster (Access mode: Standard). The installation works, but the code not. I am using the library version "graphframes:graphframes:0.8.4-spark3.5-s_2.13" and my spark version is 3.5.2.
I have also tried to install the library via pip install but no success either.
Does anyone know how to make it work ? I would like to avoid having to change my cluster's access mode.
Thanks a lot,
Sacha


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-28-2025 09:28 AM
And yes, I can confirm that it works in dedicated access mode. I've used following code:
pip install graphframes-py
from functools import reduce
from pyspark.sql import functions as F
from graphframes import GraphFrame
nodes = [
(1, "Alice", 30),
(2, "Bob", 25),
(3, "Charlie", 35)
]
nodes_df = spark.createDataFrame(nodes, ["id", "name", "age"])
edges = [
(1, 2, "friend"),
(2, 1, "friend"),
(2, 3, "friend"),
(3, 2, "enemy") # eek!
]
edges_df = spark.createDataFrame(edges, ["src", "dst", "relationship"])
g = GraphFrame(nodes_df, edges_df)
And as you can see it works as expected:

One thing to remember, Python distribution does not include JVM-core. So I had to install also this version of library on my cluster : graphframes:graphframes:0.8.3-spark3.5-s_2.13


5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-28-2025 08:40 AM
Hi @sachamourier ,
Maybe try to use Databricks Runtime ML which already includes an optimized installation of GraphFrames?
How to use GraphFrames on Azure Databricks - Azure Databricks | Microsoft Learn
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-28-2025 09:19 AM
Hi @sachamourier ,
But if you don't want to use different runtime then you need to change access mode. In standard access mode you don't have access to SparkContext which this library requires. Hence you're getting a an error like "'SparkSession' object has no attribute '_sc'" (where _sc refers to SparkContext).

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-28-2025 09:28 AM
And yes, I can confirm that it works in dedicated access mode. I've used following code:
pip install graphframes-py
from functools import reduce
from pyspark.sql import functions as F
from graphframes import GraphFrame
nodes = [
(1, "Alice", 30),
(2, "Bob", 25),
(3, "Charlie", 35)
]
nodes_df = spark.createDataFrame(nodes, ["id", "name", "age"])
edges = [
(1, 2, "friend"),
(2, 1, "friend"),
(2, 3, "friend"),
(3, 2, "enemy") # eek!
]
edges_df = spark.createDataFrame(edges, ["src", "dst", "relationship"])
g = GraphFrame(nodes_df, edges_df)
And as you can see it works as expected:
One thing to remember, Python distribution does not include JVM-core. So I had to install also this version of library on my cluster : graphframes:graphframes:0.8.3-spark3.5-s_2.13
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-29-2025 12:28 AM
@szymon_dybczak Thanks for the responses. I indeed changed my all-purpose cluster access mode and it worked. I figured that was a nicest option than changing the runtime.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-29-2025 12:34 AM
Cool, great that it worked for you!
Announcements





{kind=link}
Related Content
- EXCEL_DATA_SOURCE_NOT_ENABLED Excel data source is not enabled in this cluster in Data Engineering
- Inquiry on GraphFrame Library Upgrade Timeline for Databricks Runtime for Machine Learning in Data Engineering
- Maven libraries in VNet injected, UC enabled workspace on Standard Access Mode Cluster in Data Engineering
- Enable to use library GraphFrames in Data Engineering
- Viewing logged User input and LLM response for a Deployed Chatbot in Generative AI