Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Error in Databricks code?
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Error in Databricks code?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-05-2022 01:26 AM
https://www.databricks.com/notebooks/recitibikenycdraft/data-preparation.html
Could someone help to see in that Step 3: Prepare Calendar Info
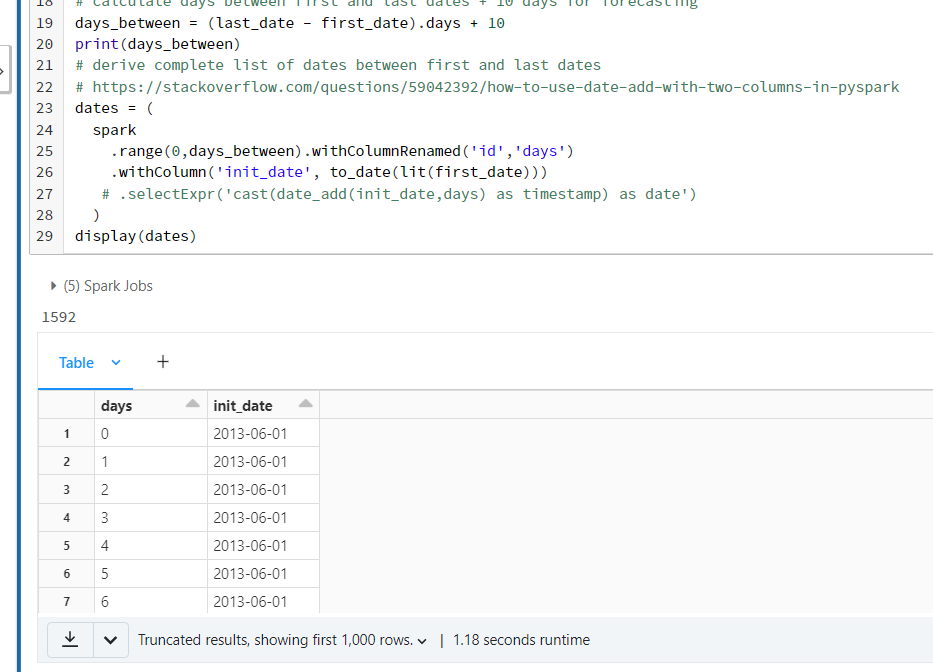
# derive complete list of dates between first and last dates
dates = (
spark
.range(0,days_between).withColumnRenamed('id','days')
.withColumn('init_date', lit(first_date))
.selectExpr('cast(date_add(init_date, days) as timestamp) as date')
)
what does 'days' refer to in the last selectExpr sentence? it seems to be me not defined. is it meant to be 'days_between'? If i replace 'days' with 'days_between', it also breaks, because it expects a integer value, and not a variable.
Thanks.


6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-05-2022 06:00 AM
@THIAM HUAT TAN
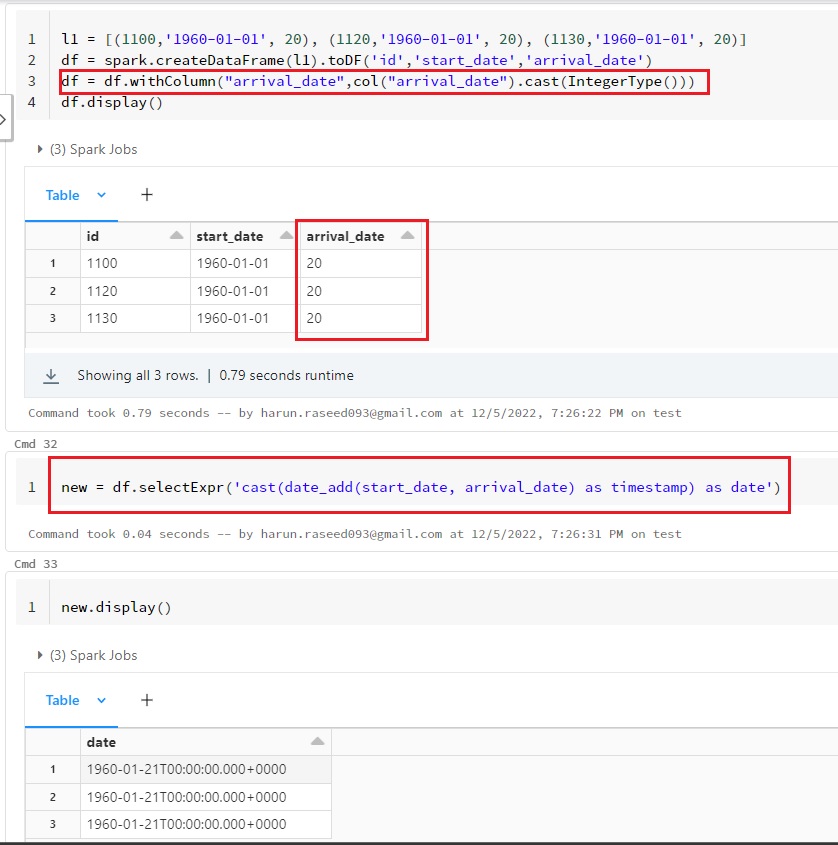
You are renaming the "id" column to "days", that days column should have a integer value. and in the selectExpr you are doing a date addtion of init_date and the values from days column.
I have recreated the same with a sample data set.
Note : Kindly check whether the "id" column is a integer in your case.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-05-2022 06:08 PM
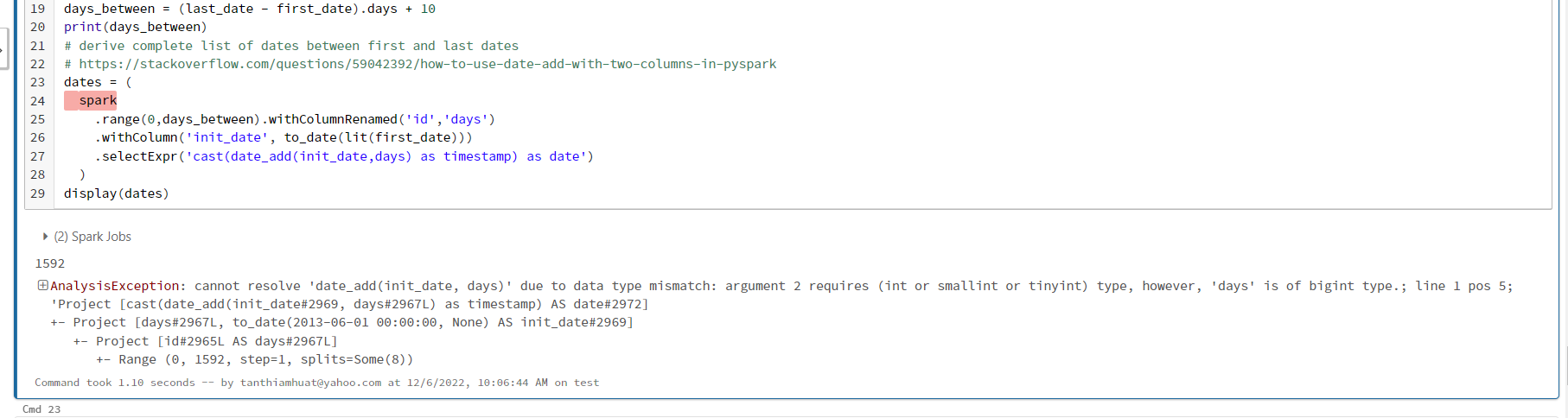
thanks Harun for your example.. however, I am still stuck.. initially I have thought it is due to the date with time that interfere with the date_add, and I make it with to_date, however, the same error message appear.


Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-05-2022 06:38 PM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-06-2022 01:41 AM
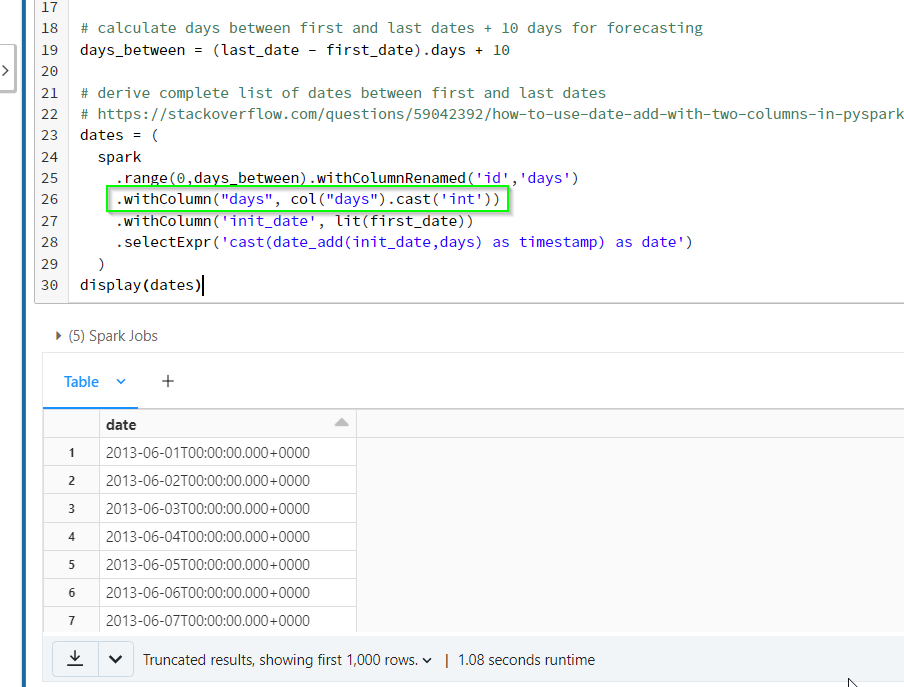
@THIAM HUAT TAN Kindly cast the "id" column to IntegerType like how i have casted for "arrival_date" column in my above sample record snapshot. That will make the code work.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-06-2022 06:31 PM
yes, it should work similarly, thanks.
cast('int') vs cast(IntegerType()), I suppose both are identical?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-05-2022 09:31 AM
Hi @THIAM HUAT TAN
In your notebook, you are creating a integer column days_between with the code
days_between = (last_date - first_date).days + 10Logically speaking, what the nb trying to do is to fetch all the dates between two dates to do a forecast.
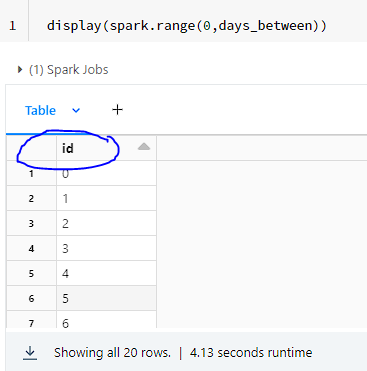
So, to get a complete list of dates between the start date and x number of days into the future (x = days_between), you are using spark.range(0,days_between). What is does is that it fetches a column of integers just like how python range works. The name of the column would be by default ''id".

The date calculated would be nothing but first_date + days.
Hope this helps...
Cheers..
Uma Mahesh D
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Use of Genie agents for ETL migration in Data Engineering
- Reducing Time to Help in the Databricks Community in Data Engineering
- Pipeline still needs USE SCHEMA on an old schema it no longer writes to in Data Governance
- Getting error in databricks agent response in Generative AI
- Materialized View backing pipeline retains old Unity Catalog after catalog rename in Data Engineering