Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Event hub streaming improve processing rate
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Event hub streaming improve processing rate
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-21-2021 02:50 PM
Hi all,
I'm working with event hubs and data bricks to process and enrich data in real-time.
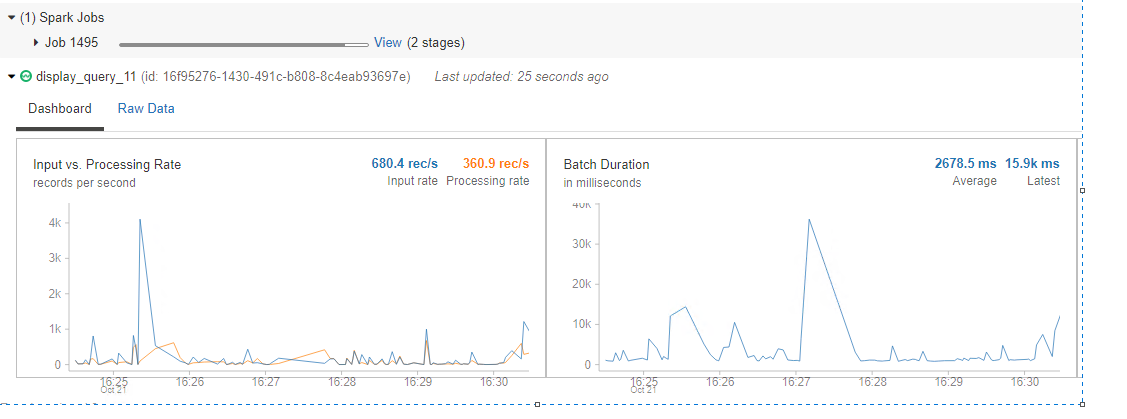
Doing a "simple" test, I'm getting some weird values (input rate vs processing rate) and I think I'm losing data:

The script that I'm using is:
conf = {}
conf['eventhubs.connectionString'] = sc._jvm.org.apache.spark.eventhubs.EventHubsUtils.encrypt(connectionString_bb_stream)
conf['eventhubs.consumerGroup'] = 'adb_jr_tesst'
conf['maxEventsPerTrigger'] = '350000'
conf['maxRatePerPartition'] = '350000'
conf['setStartingPosition'] = sc._jvm.org.apache.spark.eventhubs.EventPosition.fromEndOfStream
df = (spark.readStream
.format("eventhubs")
.options(**conf)
.load()
)
json_df = df.withColumn("body", from_json(col("body").cast('String'), jsonSchema))
Final_df = json_df.select(["sequenceNumber","offset", "enqueuedTime",col("body.*")])
Final_df = Final_df.withColumn("Key", sha2(concat(col('EquipmentId'), col('TagId'), col('Timestamp')), 256))
Final_df.display()can you help me to understand why I'm "losing" data or how I can improve the process?
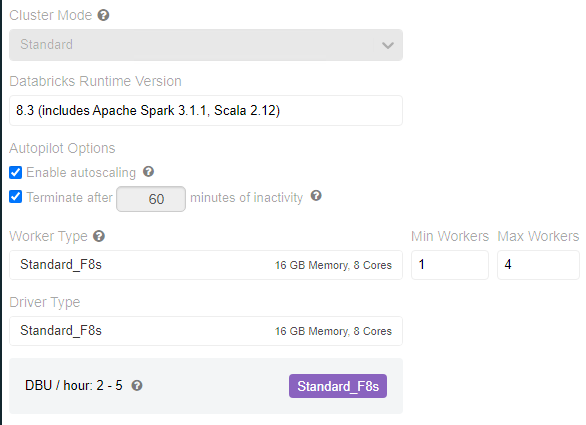
The cluster that I'm using is:

I think is a cluster configuration issue, but I'm not sure how to tackle that.
Thanks for the help, guys!
Labels:
- Labels:
-
Azure event hub
-
Data
-
Event
-
Eventhub
-
Records


13 REPLIES 13
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-21-2021 09:11 PM
Hi kaniz,
Thanks for your reply.
Thanks for your reply.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 11:42 AM
Hi @Kaniz Fatma , sorry for bothering you,
could you please take a look at this?
Thanks for your help!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-21-2021 11:12 PM
Ok, the only thing I notice is that you have set a termination time which is not necessary for streaming (if you are doing real-time).
I also notice you do not set a checkpoint location, something you might consider.
You can also try to remove the maxEvent and maxRate config.
A snippet from the docs:
Here are the details of the recommended job configuration.
- Cluster: Set this always to use a new cluster and use the latest Spark version (or at least version 2.1). Queries started in Spark 2.1 and above are recoverable after query and Spark version upgrades.
- Alerts: Set this if you want email notification on failures.
- Schedule: Do not set a schedule.
- Timeout: Do not set a timeout. Streaming queries run for an indefinitely long time.
- Maximum concurrent runs: Set to 1. There must be only one instance of each query concurrently active.
- Retries: Set to Unlimited.
https://docs.databricks.com/spark/latest/structured-streaming/production.html
https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 04:27 AM
Thanks for the answer werners.
What do you mean when you say 'I have set a termination'? In wich part of the script?
I'm not using a check point because I just wanted see what is de behavior of the process at the beginning and try to figure out why I'm losing information.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 04:28 AM
The termination time in the cluster settings
(Terminate after 60 minutes of inactivity)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 04:33 AM
Ah OK, I have that parameter only for the dev cluster.
is possible that the issues is related to this?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 04:36 AM
Maybe, if your cluster shuts down your streaming will be interupted.
But in your case that is probably not the issue as it seems you are not running a long running streaming query.
But what makes you think you have missing records?
Did you count the #records incoming and outgoing?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 04:44 AM
Yes, I've counted the records for a specific range of time (5 min) and there is like +4k records missing... And is aligned with the streaming graph of the processing vs input rate... So, if I'm not losing data I'm not processing in a near real-time the records.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 05:20 AM
Hm odd. You don't use spot instances do you?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 05:54 AM
Sorry Werners, I'm not sure what do you mean with "sport instances"
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 06:28 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 06:50 AM
Thanks for the explanation.
I don't have that option checked.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2021 03:24 PM
hi @Jhonatan Reyes ,
How many Event hubs partitions are you readying from? your micro-batch takes a few milliseconds to complete, which I think is good time, but I would like to undertand better what are you trying to improve here.
Also, in this case you are using memory sink (display), I will highly recommend to test it using another type of sink.
Announcements





{kind=link}
{kind=link}
{kind=link}
Related Content
- Autoscaling with the autoloader without SDP in Data Engineering
- Performance optimization on auto_cdc_flow in Data Engineering
- Is Lakeflow Connect SCD Type 2 output is incompatible with Spark dec pipeline streaming tables? in Data Engineering
- Auto Loader with ignoreMissingFiles and useManagedFileEvents fails on Classic Compute in Data Engineering
- Testing ai_parse_document vs PyMuPDF for PDF extraction in Generative AI