Hi @WYO
If it is comparing against on-prem data, I would recommend an efficient approach as below. All you need is to establish a connection to on-prem database using the jdbc configuration as below.
Step 1 - Establish connection to the on-prem database
# On prem Sql server details
jdbcHostname = "OnPremServerName"
jdbcPort = "portnumber"
jdbcDatabase = "DatabaseName"
dbServerUserName = "serviceaccountuser"
dbServerPassword = dbutils.secrets.get("scope",key="serviceaccountuserpwd")
# Service account credentials string for the on prem sql server
properties = {"user" : dbServerUserName,"password" : dbServerPassword }
# connection string for the on prem sql server
url = "jdbc:sqlserver://{0}:{1};database={2};trustServerCertificate=true;loginTimeout=30;hostNameInCertificate=*.database.windows.net;".format(jdbcHostname,jdbcPort,jdbcDatabase)
# query a table from the on prem sql server
query = "(SELECT * FROM [dbo].[table]) datasource"
# read to a dataframe from the on prem sql server
df_onprem = spark.read.jdbc(url=url, table=query, properties=properties)
#view data
display(df_onprem)
Step 2 - Read delta table into the datafame
df_deltatable = spark.sql("select * from catalog.schema.table")
display(df_deltatable)
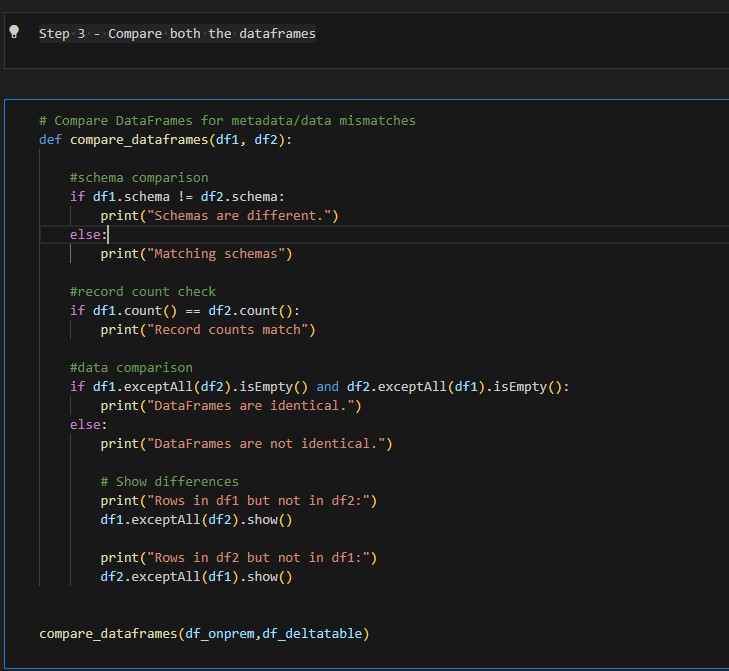
Step 3 - Compare both the dataframes
# Compare DataFrames for metadata/data mismatches
def compare_dataframes(df1, df2):
#schema comparison
if df1.schema != df2.schema:
print("Schemas are different.")
else:
print("Matching schemas")
#record count check
if df1.count() == df2.count():
print("Record counts match")
#data comparison
if df1.exceptAll(df2).isEmpty() and df2.exceptAll(df1).isEmpty():
print("DataFrames are identical.")
else:
print("DataFrames are not identical.")
# Show differences
print("Rows in df1 but not in df2:")
df1.exceptAll(df2).show()
print("Rows in df2 but not in df1:")
df2.exceptAll(df1).show()
compare_dataframes(df_onprem,df_deltatable)
My response is not getting through with formatted code (attachments fyr)
Let me know for anything, else, please mark this as a solution.







{kind=link}
{kind=link}