Hi @Yogybricks
Hope you are well. Just wanted to see if you were able to find an answer to your question and would you like to mark an answer as best? It would be really helpful for the other members too.
Cheers!
Hi @zsucic1
Hope you are well. Just wanted to see if you were able to find an answer to your question and would you like to mark an answer as best? It would be really helpful for the other members too.
Cheers!
Hello!I am contacting you because of the following problem I am having:In an ADLS folder I have two items, a folder and an automatically generated Block blob file with the same name as the folder.I want to use the dbutils.fs.mv command to move the fo...
Hi @SaraCorralLou
Thank you for posting your question in our community! We are happy to assist you.
To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answer...
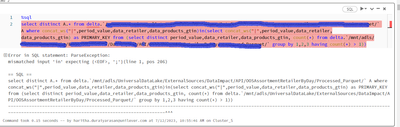
Hi,From the error , it looks like there is no space between the brackets and the "in" keyword after the where clause. Can you please try again see if you facing the same error.
Hello,After implementing the use of Secret Scope to store Secrets in an azure key vault, i faced a problem.When writting an output to the blob i get the following error:shaded.databricks.org.apache.hadoop.fs.azure.AzureException: Unable to access con...
Hi all thank you for the suggestions. Doing This spark.conf.set("fs.azure.account.key.{storage_account}.dfs.core.windows.net", "{myStorageAccountKey}")For the hadoop configuration does not work.And the suggestion of @Tharun-Kumar would suggest to har...
Hello!We are developing a web application in .NET, we need to consume data in gold layer, (as if we had a relational database), how can we do it? export data to sql server from gold layer?
Hi @apiury
Thank you for posting your question in our community! We are happy to assist you.
To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your ...
I have a dataframe that has 5M rows. I need to split it up into 5 dataframes of ~1M rows each.
This would be easy if I could create a column that contains Row ID. Is that possible?
Hi @NithinTiruveedh
Thank you for posting your question in our community! We are happy to assist you.
To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answ...
Hi All,I am running a sample notebook from Databricks Documentation section on Higher Order Function on my community edition. I am running this notebook on DBR 12.2 LTS.Databricks Documentation URL : https://docs.databricks.com/optimizations/higher-o...
Any suggestions on how to stream data from databricks into snowflake?. Is snowpipe is the only option?. Snowpipe is not faster since it runs copy into in a small batch intervals and not in few seconds. If no option other than snowpipe, how to call it...
Hi @babyhari
Hope everything is going great.
Just wanted to check in if you were able to resolve your issue. If yes, would you be happy to mark an answer as best so that other members can find the solution more quickly? If not, please tell us so we ...
We were finally able to get DLT pipelines to run the optimize and vacuum automatically. We verified this via the the table history. However I am able to still query versions older than 7 days. Has anyone been experiencing this and how were you a...
Hi @Gil
Hope all is well! Just wanted to check in if you were able to resolve your issue and would you be happy to share the solution or mark an answer as best? Else please let us know if you need more help.
We'd love to hear from you.
Thanks!
Dear @Werner Stinckens and @Tyler Retzlaff We would like to express our gratitude for your participation and dedication in the Databricks Community last week. Your interactions with customers have been valuable and we truly appreciate the time...
Let's say I create a table like CREATE TABLE IF NOT EXISTS new_db.data_table (
key STRING,
value STRING,
last_updated_time TIMESTAMP
) USING DELTA LOCATION 's3://......';Now when I insert into this table I insert data which has say 20 columns a...
I tried running "REFRESH TABLE tablename;" but I still do not see the added columns in the data explorer columns, while I do see the added columns in the sample data
I am trying to write a code for Error Handling in Databricks notebook in case of a SQL magic cell failure. I have a %sql cell followed by some python code in next cells. I want to abort the notebook if the query in %sql cell fails. To do so I am look...
Hi @pjain
We haven't heard from you since the last response from @daniel_sahal , and I was checking back to see if her suggestions helped you.
Or else, If you have any solution, please share it with the community, as it can be helpful to others.
A...
Hi, I'm trying to write data from RDD to the storage account:Adding storage account key:spark.conf.set("fs.azure.account.key.y.blob.core.windows.net", "myStorageAccountKey")Read and write to the same storage:val path = "wasbs://x@y.blob.core.windows....
Hello @Vadim1 and @User16764241763. I'm wondering if you find a way to avoid adding the hardcoded key in the advanced options spark config section in the cluster configuration. Is there a similar command to spark.conf.set("spark.hadoop.fs.azure.accou...