Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
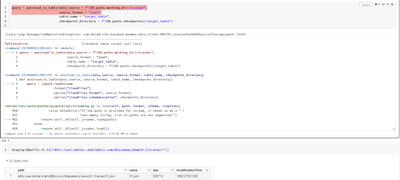
Tree-based estimators in pyspark.ml have an argument called checkpointIntervalcheckpointInterval = Param(parent='undefined', name='checkpointInterval', doc='set checkpoint interval (>= 1) or disable checkpoint (-1). E.g. 10 means that the cache will ...
@Federico Trifoglio :If sc.getCheckpointDir() returns None, it means that no checkpoint directory is set in the SparkContext. In this case, the checkpointInterval argument will indeed be ignored. To set a checkpoint directory, you can use the SparkC...