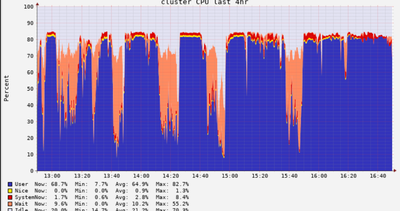
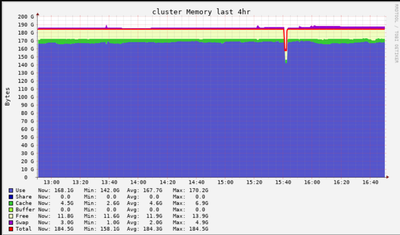
- 1474 Views
- 0 replies
- 0 kudos
Why am I not able to view all table properties?
We have a live streaming table created using the commandCREATE OR REFRESH STREAMING LIVE TABLE foo TBLPROPERTIES ( "pipelines.autoOptimize.zOrderCols" = "c1,, c2, c3, c4", "delta.randomizeFilePrefixes" = "true" );But when I run the show table propert...
- 1474 Views
- 0 replies
- 0 kudos