Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Azure Databricks VM type for OPTIMIZE with ZORDER ...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Azure Databricks VM type for OPTIMIZE with ZORDER on a single column
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-22-2022 09:59 AM
Dears
I was trying to check what Azure Databricks VM type is best suited for executing OPTIMIZE with ZORDER on a single timestamp value (but string data type) column for around 5000+ tables in the Delta Lake.
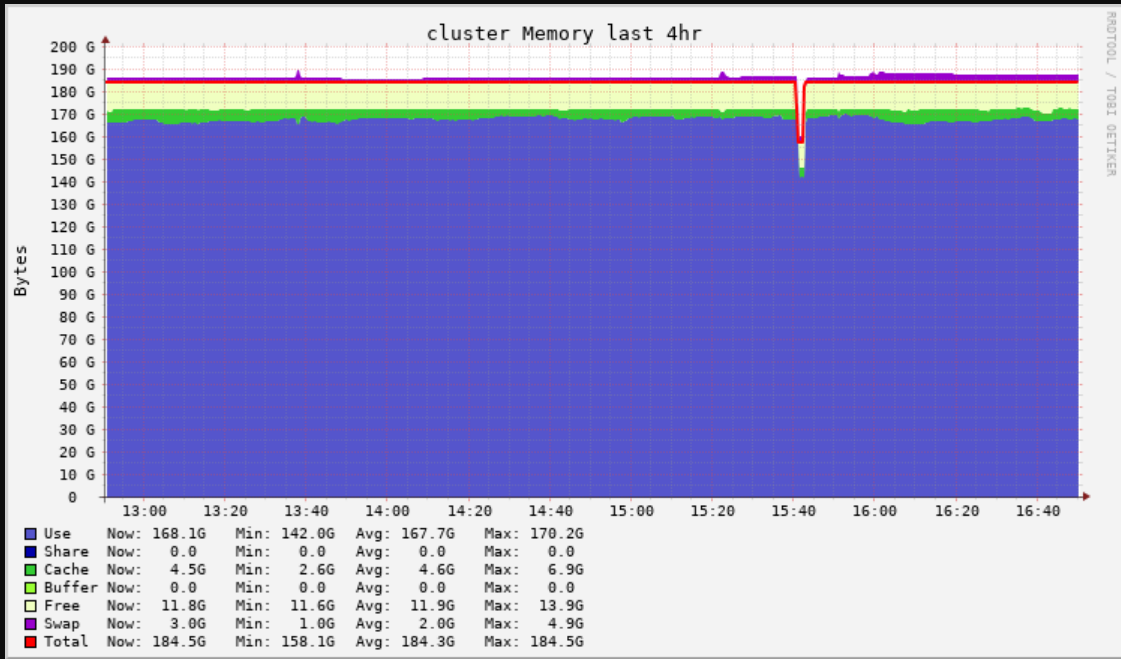
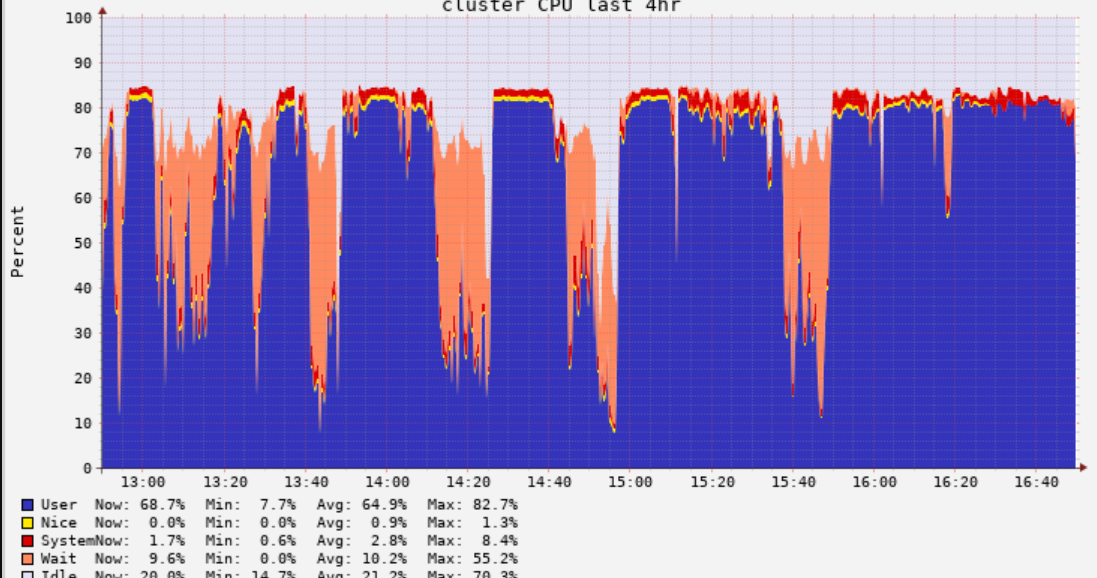
I chose Standard_F16s_v2 with 6 workers & 1 driver. (> so, this gives total 112 CPUs, 185 GB Memory, 7571.4 GB OS disk storage). We are in 9.1 LTS. Given below is some information on how the CPU and the memory usage looks like. Also, in "Storage" tab of Spark UI, I do not see any Cache misses but there is lot of shuffle read in "Executors" tab. The job is running for 7+ hours, and I see still 216 active stages, and 219 pending stages (this number keeps changing). spark.sql.shuffle.partitions is set to default.
My question is : based on the information provided here, which series VM is best suitable? Also, any other sort of optimization that can be done? If I go with the best practice to set shuffle partitions value as 2 * number of cores, the default value still suits.




Labels:
- Labels:
-
Delt Lake
-
Optimize Command
-
Zorder


4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-23-2022 01:54 PM
Your chart; its nice (compared to other ones which I see); it seems you utilize your cluster correctly.
You can check in Spark UI for data spills - are Spark partitions fit in memory?
Any cluster should be okay if your disk partition size for your tables is around 200 MB (optimal size). Then, of course, you can do benchmarking. Usually, new versions of machines are a bit faster.
Tooptimizationstimzations for tables where you append data is good to use disk partitioning per date or month. Then, do OPTIMIZATION with the WHERE clause to limit it to only new partitions.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-24-2022 11:19 AM
Hi Hubert,
In screenshot#3 I put above, there is plenty of shuffle read? Is that what needs to be checked for data spills?
Also, please let me know how I can set this flag - disk partition size for your tables is around 200 MB (optimal size).
Appreciate, and thanks in advance.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-24-2022 10:39 AM
Hi,
The Standard_F16s_v2 is a compute optimize type machine.
On the other-hand, for delta optimize (both bin-packing and Z-Ordering), we recommend Stabdard_DS_v2-series. Also, follow Hubert's recommendations.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-24-2022 11:20 AM
Hi Jose,
Thanks for the quick reply. Yes, I plan to test now with DdS_V5 series, as DdS series seems to be delta cache accelerated where as other DS series seem to be falling under "General Purpose" workload machines.
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Models failing in tutorial in Machine Learning
- Why We Moved Our Operational Database Into Databricks — And Stopped Managing Two Stacks in Data Engineering
- ANALYZE TABLE ... COMPUTE STATISTICS FOR ALL COLUMNS silently does not update column stats on DBR 15 in Data Engineering
- Is Databricks AI/BI Genie worth it if we already have Power BI or Tableau? in Data Engineering
- Genie Space API – Inspect Mode Limitation in Generative AI