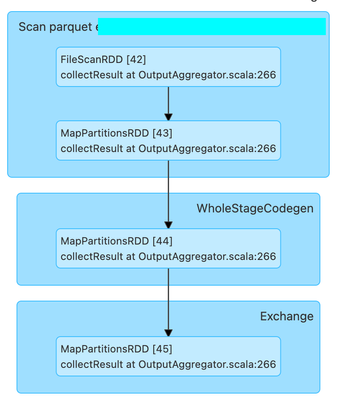
My company urgently needs help, we are having severe performance problems with spark and are having to switch to a different solution if we don't get to the bottom of it.
We are on 1.3.1, using spark SQL, ORC Files with partitions and caching in me...
Hi @msj50 , Thank you for posting your question in our community! We are happy to assist you.
To help us provide you with the most accurate information, could you please take a moment to review the responses and select the one that best answers your ...
Hii'm looking for performance test tool.I saw that there was apost about jmeter https://stackoverflow.com/questions/66913893/how-can-i-connect-jmeter-with-databricks-spark-cluster#comment118293766_66915965 , however, the jdbc paraeters are requesting...
Hi @Amit Cahanovich Great to meet you, and thanks for your question! Let's see if your peers in the community have an answer to your question. Thanks.
We are having some issues with merge performance, so I went and read a bit in the documentation, I found this section:https://docs.databricks.com/delta/tune-file-size.html#autotune-file-size-based-on-workload"Databricks recommends setting the table p...
Hi,Do you know any good resources about Databricks performance improvements(like improving query performances, monitoring/resolving performance bottlenecks etc)?Thanks
Hi @Ömer Özsakarya We haven't heard from you since the last response from @Lakshay Goel , and I was checking back to see if her suggestions helped you.Or else, If you have any solution, please share it with the community, as it can be helpful to ...
I already improved a lot the performances of our ETL (x20 !) but I still want to know where I can improve performances. I seems that tables stats and column indexing slow down a bit writings so I want to decrease dataSkippingNumIndexedCols to match t...
I am using Databricks in Azure. I want to mount ADLS Gen2 on Databricks and create unmanged (external) tables on the mount point. But before that I want to know which will give best performance, is it Managed table (stores data in DBFS root)or Un-ma...
Hi @Paramesh Malla Thank you for your question! To assist you better, please take a moment to review the answer and let me know if it best fits your needs.Please help us select the best solution by clicking on "Select As Best" if it does.Your feedba...
Hi, I need to analyse performance issues for databricks. Is there any document or monitoring tool to run to see what is happening in databricks? I am very new in databricks. Best
Typo error in my second point of the previous post. Click the execution plan of your task[this is available under SQL/Dataframe tab in Spark UI]. It explains what operations run in the photon engine and what didn't execute by photon.
Hi All, I would you to get some ideas on how to improve performance on a data frame with around 10M rows. adls- gen2df1 =source1 , format , parquet ( 10 m)df2 =source2 , format , parquet ( 10 m)df = join df1 and df2 type =inner join df.count() is ...
I have a table, full scan of which takes ~20 minutes on my cluster. The table has "Time" TIMESTAMP column and "day" DATE column. The latter is computed (manually) as "Time" truncated to day and used for partitioning.I query the table using predicate ...
Hi @Vladimir Ryabtsev, We haven’t heard from you since the last response from @Uma Maheswara Rao Desula, and I was checking back to see if their suggestions helped you.Or else, If you have any solution, please share it with the community, as it c...
So databricks gives us great toolkit in the form optimization and vacuum. But, in terms of operationaling them, I am really confused on the best practice.Should we enable "optimized writes" by setting the following at a workspace level?spark.conf.set...
@AKSHAY PALLERLA Just checking in to see if you got a solution to the issue you shared above. Let us know!Thanks to @Werner Stinckens for jumping in, as always!
getting error as below while creating buckets on delta table.Error in SQL statement: AnalysisException: Delta bucketed tables are not supported.have fall back to parquet table due to this for some use cases. is their any alternative for this. i have...
Hi @Rahul Samant , we checked internally on this due to certain limitations bucketing is not supported on delta tables, the only alternative for bucketing is to leverage the z ordering, below is the link for reference https://docs.databricks.com/de...
Hi, I am using databricks to load data from one delta table into another delta table.
I'm using SIMBA Spark JDBC connector to pull data from delta table in my source instance and writing into delta table in my databricks instance.
The source has...
When I'm running TPC-DS (1TB) benchmark on Photon 10.2 and I see the following failures: Queries Q06, Q09 and Q41 fail with the error "Query: AEValueSubQuery is not supported". Q66 fails with the error "[MISSING_COLUMN] org.apache.spark.sql.A...
Specifically for write and read streaming data to HDFS or s3 etc. For IoT specific scenario how it performs on time series transactional data. Can we consider delta table as time series table?