- 4312 Views
- 3 replies
- 2 kudos
Error while optimizing the table . Failure of InSet.sql for UTF8String collection
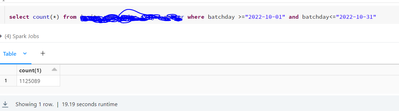
count of the table : 1125089 for october month data , So I am optimizing the table. optimize table where batchday >="2022-10-01" and batchday<="2022-10-31"I am getting error like : GC overhead limit exceeded at org.apache.spark.unsafe.types.UTF8St...
- 4312 Views
- 3 replies
- 2 kudos
Latest Reply
- 2 kudos
Hi @Nagini Sitaraman To understand the issue better I would like to get some more information. Does the error occur at the driver side or executor side? Can you please share the full error stack trace? You may need to check the spark UI to find wher...
- 2 kudos