Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Generate Group Id for similar deduplicate values o...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Generate Group Id for similar deduplicate values of a dataframe column.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2022 10:37 PM
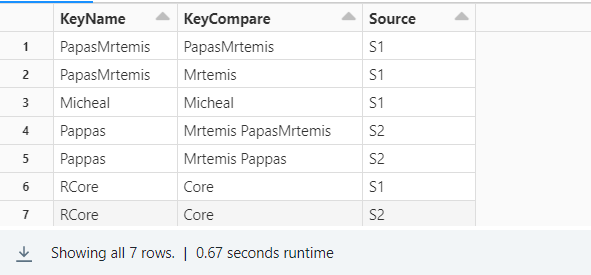
Inupt DataFrame
'''
KeyName KeyCompare Source
PapasMrtemis PapasMrtemis S1
PapasMrtemis Pappas, Mrtemis S1
Pappas, Mrtemis PapasMrtemis S2
Pappas, Mrtemis Pappas, Mrtemis S2
Micheal Micheal S1
RCore Core S1
RCore Core,R S2
'''
Names are coming from the different source after doing a union those applied fuzzy match on it. now irrespective of sources need a group Id for similar values.
I want to use pyspark.
Output should be like below.
'''
KeyName KeyCompare Source KeyId
PapasMrtemis PapasMrtemis S1 1
PapasMrtemis Pappas, Mrtemis S1 1
Pappas, Mrtemis PapasMrtemis S2 1
Pappas, Mrtemis Pappas, Mrtemis S2 1
Micheal Micheal S1 2
RCore Core S1 3
RCore Core,R S2 3
'''


6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-22-2022 11:23 PM
https://sparkbyexamples.com/pyspark/pyspark-distinct-to-drop-duplicates/
refer this link above may match with your concern. hope this can make and help in this case
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2022 12:36 AM
Please refer https://www.geeksforgeeks.org/how-to-count-unique-id-after-groupby-in-pyspark-dataframe/ this link this might help you
Ajay Kumar Pandey
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-23-2022 05:43 AM
Hi @Adi dev ,
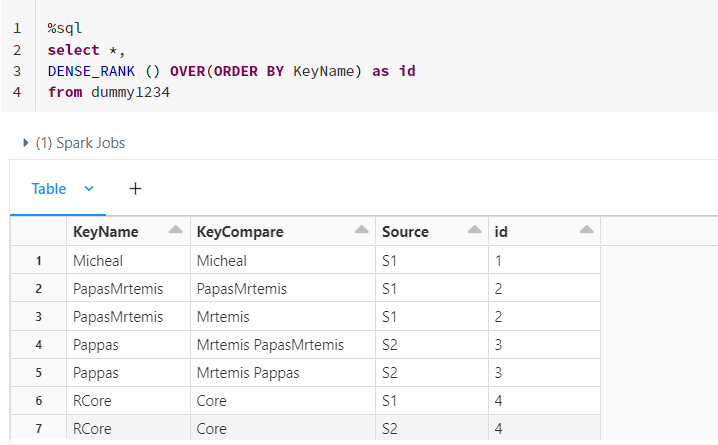
Your requirement can be easily achieved by using a dense_rank() function.
As your data looks a bit confusing, creating a sample data on my own and assigning a group id based on KeyName. If you want to assign group id based on other column/s, you can add those to ORDER BY clause accordingly.
Input :

Output:

Hope this helps..Cheers.
Uma Mahesh D
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-29-2022 01:39 PM
Use hash function on the retrieved columns to generate a unique hash value on the basis of the value in these columns. If the same values will be there in two rows then same hash will be generated by the function and then system won't allow it. Hence, you will be able to get unique for each record deduplicated.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-02-2022 12:22 PM
- Create a UDF where you pass all the fields as Input that you need to take into consideration for a unique row.
- Create a list by splitting based on ' ' or ','.
- sort the list and
- concat all the elements of the list to derive "new field".
- Calculate dense_rank based on the derived field .
- Remove "new field".
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-22-2026 02:07 PM
Hey. We’ve run into similar deduplication problems before. If the name differences are pretty minor (punctuation, spacing, small typos), fuzzy string matching can usually get you most of the way there. That kind of similarity-based clustering works fine for straightforward cases.
Once names start to vary more though (abbreviations, reordered components, nicknames, or spellings that don’t look alike character-wise), fuzzy matching starts to fall apart because it’s only comparing characters, not meaning. That’s where semantic understanding helps.
In practice, fuzzy matching missed things like “A. Butoi” vs “Alexandra Butoi”, while a semantic approach did much better overall. You can read more in the FutureSearch case study here: https://futuresearch.ai/researcher-dedupe-case-study/
Announcements





{kind=link}
{kind=link}
Related Content
- Slow Delta write when creating embeddings with mapPartitions in Generative AI
- Can’t save results to target table – out-of-memory error in Data Engineering
- Generate embeddings for 50 million rows in dataframe in Data Engineering
- Spark JDBC Write Fails for Record Not Present - PK error in Data Engineering
- DLT Pipeline and Pivot tables in Data Engineering