Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Getting Authentication Error while accessing Azure...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-10-2022 05:07 PM
I am trying to access the Azure Blob table using Pyspark but getting an Authentication Error. Here I am passing SAS token (HTTP and HTTPS enabled) but it's working only with WASBS (HTTPS) URL, not with WASB (HTTP) URL.
Even I tried with Account key as well but didn't work.
The other way is working fine if I try to load the parquet file by passing the WASB URL, but this method is very slow and takes too much time to access the data.
Please help me understand why PySpark-Azure showing such behaviour.
We had a meeting with the Azure support team as well but they also couldn't find any issue from their end
Sample Code:
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
spark.conf.set("fs.azure.sas.<container-name>.<storage-account>.blob.core.windows.net","<
SAS Token>")
Error Details:
Py4JJavaError: An error occurred while calling o146.table.
: java.util.concurrent.ExecutionException: org.apache.hadoop.fs.azure.AzureException: com.microsoft.azure.storage.StorageException: Cannot use HTTP with credentials that only support HTTPS.
at org.sparkproject.guava.util.concurrent.AbstractFuture$Sync.getValue(AbstractFuture.java:306)
at org.sparkproject.guava.util.concurrent.AbstractFuture$Sync.get(AbstractFuture.java:293)
at org.sparkproject.guava.util.concurrent.AbstractFuture.get(AbstractFuture.java:116)
at org.sparkproject.guava.util.concurrent.Uninterruptibles.getUninterruptibly(Uninterruptibles.java:135)
at org.sparkproject.guava.cache.LocalCache$Segment.getAndRecordStats(LocalCache.java:2410)
at org.sparkproject.guava.cache.LocalCache$Segment.loadSync(LocalCache.java:2380)
at org.sparkproject.guava.cache.LocalCache$Segment.lockedGetOrLoad(LocalCache.java:2342)
at org.sparkproject.guava.cache.LocalCache$Segment.get(LocalCache.java:2257)
at org.sparkproject.guava.cache.LocalCache.get(LocalCache.java:4000)
at org.sparkproject.guava.cache.LocalCache$LocalManualCache.get(LocalCache.java:4789)
at org.apache.spark.sql.catalyst.catalog.SessionCatalog.getCachedPlan(SessionCatalog.scala:155)
at org.apache.spark.sql.execution.datasources.FindDataSourceTable.org$apache$spark$sql$execution$datasources$FindDataSourceTable$$readDataSourceTable(DataSourceStrategy.scala:249)
at org.apache.spark.sql.execution.datasources.FindDataSourceTable$$anonfun$apply$2.applyOrElse(DataSourceStrategy.scala:288)
at org.apache.spark.sql.execution.datasources.FindDataSourceTable$$anonfun$apply$2.applyOrElse(DataSourceStrategy.scala:278)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsDown$2(AnalysisHelper.scala:108)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:74)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsDown$1(AnalysisHelper.scala:108)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:221)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsDown(AnalysisHelper.scala:106)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsDown$(AnalysisHelper.scala:104)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsDown(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsDown$4(AnalysisHelper.scala:113)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$mapChildren$1(TreeNode.scala:408)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapProductIterator(TreeNode.scala:244)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:406)
at org.apache.spark.sql.catalyst.trees.TreeNode.mapChildren(TreeNode.scala:359)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.$anonfun$resolveOperatorsDown$1(AnalysisHelper.scala:113)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper$.allowInvokingTransformsInAnalyzer(AnalysisHelper.scala:221)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsDown(AnalysisHelper.scala:106)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperatorsDown$(AnalysisHelper.scala:104)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.resolveOperatorsDown(LogicalPlan.scala:29)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperators(AnalysisHelper.scala:73)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.resolveOperators$(AnalysisHelper.scala:72)
at 

1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-12-2022 03:42 AM
Hi @Arvind Ravish
The issue got fixed after passing HTTP and HTTPS enabled token to spark executors.
Thanks again for your help
3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-12-2022 12:02 AM
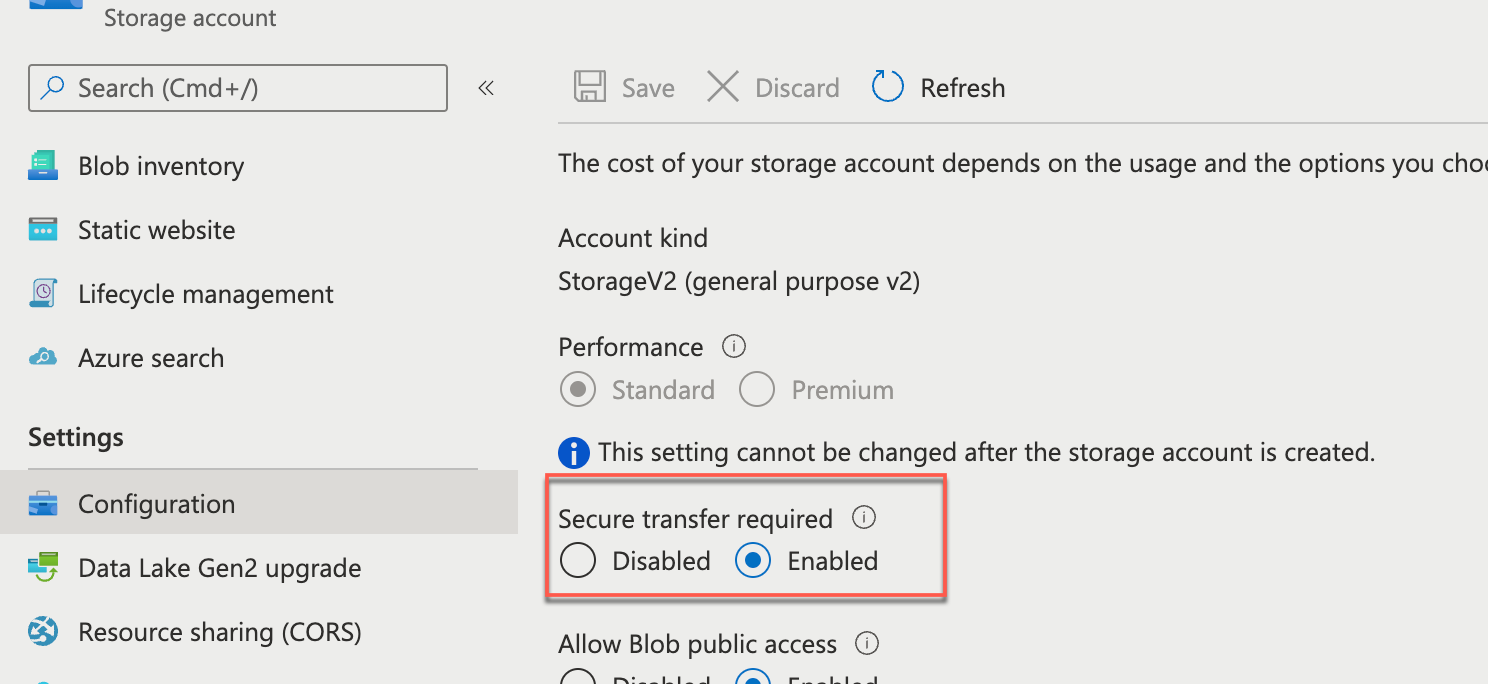
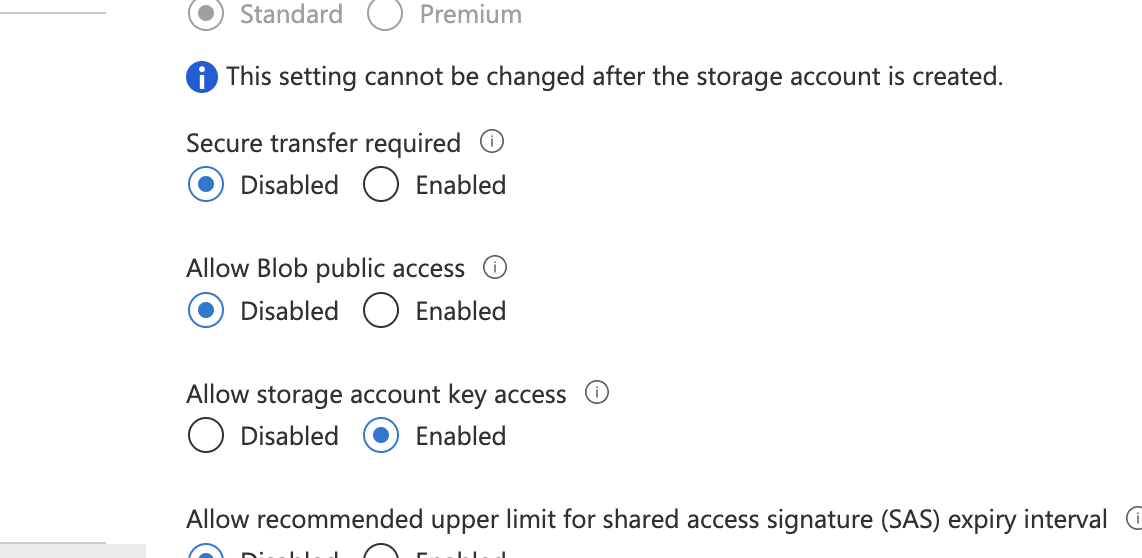
Based on your error you have enabled Secure transfer enabled on the storage account.
You can disable the below setting and try again with WASB/HTTP
https://docs.microsoft.com/en-us/azure/storage/common/storage-require-secure-transfer

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-12-2022 12:07 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-12-2022 03:42 AM
Hi @Arvind Ravish
The issue got fixed after passing HTTP and HTTPS enabled token to spark executors.
Thanks again for your help
Announcements





{kind=link}
{kind=link}
Related Content
- Databricks Apps - "App Not Available" error with locationId parameter missing in Data Engineering
- Five Unity Catalog ABAC Updates Worth Paying Attention To in Data Governance
- DLT pipeline production deployment with AWS in Administration & Architecture
- Observable API and Delta Table merge in Data Engineering
- Configure SAS Token for ADLS Access in Databricks Job (Works on Classic Cluster, Fails on Serverless in Data Engineering