My two dataframes look like new_df2_record1 and new_df2_record2 and the expected output dataframe I want is like new_df2:

The code I have tried is the following:
If I print the top 5 rows of new_df2, it gives the output as expected but I cannot print the total count or the number of total number of columns it contains. Gives the error:
"ERROR Executor: Exception in task 2.0 in stage 6.0 (TID
😎org.apache.spark.api.python.PythonException: Traceback (most recent call last):
File "D:\Spark\python\lib\pyspark.zip\pyspark\worker.py", line 604, in main
File "D:\Spark\python\lib\pyspark.zip\pyspark\worker.py", line 596, in process
File "D:\Spark\python\lib\pyspark.zip\pyspark\serializers.py", line 259, in dump_stream
vs = list(itertools.islice(iterator, batch))
File "D:\Spark\python\lib\pyspark.zip\pyspark\serializers.py", line 326, in _load_stream_without_unbatching
" in batches: (%d, %d)" % (len(key_batch), len(val_batch)))
ValueError: Can not deserialize PairRDD with different number of items in batches: (4096, 8192)"from pyspark.sql.types import StructType
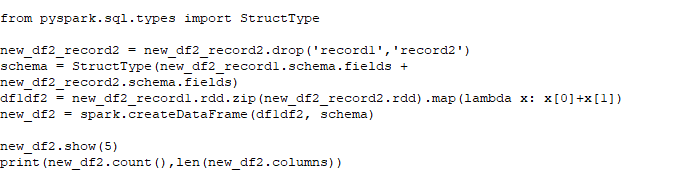
new_df2_record2 = new_df2_record2.drop('record1','record2') schema = StructType(new_df2_record1.schema.fields + new_df2_record2.schema.fields) df1df2 = new_df2_record1.rdd.zip(new_df2_record2.rdd).map(lambda x: x[0]+x[1]) new_df2 = spark.createDataFrame(df1df2, schema)
new_df2.show(5) print(new_df2.count(),len(new_df2.columns))








{kind=link}
{kind=link}