Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: How can we write a pandas dataframe into azure...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How can we write a pandas dataframe into azure adls as excel file, when trying to write it is showing error as protocol not known 'abfss' like that.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2023 01:08 AM


13 REPLIES 13
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2023 02:35 AM
Can you please share the code snippet?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2023 05:56 AM
Currently, as per my understanding, there is no support available in databricks to write into excel file using python. Suggested solution would be to convert pandas Dataframe to spark Dataframe and then use Spark Excel connector to write into excel files. This link explains the details clearly for the same requirement.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2023 05:16 AM
so for that we don't have a option to add background color and not able to autofit the rows and columns
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2023 07:00 AM
hey
you need to authenticate the abfss
Configure authentication
service_credential = dbutils.secrets.get(scope="<scope>",key="<service-credential-key>")
spark.conf.set("fs.azure.account.auth.type.<storage-account>.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.<storage-account>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.<storage-account>.dfs.core.windows.net", "<application-id>")
spark.conf.set("fs.azure.account.oauth2.client.secret.<storage-account>.dfs.core.windows.net", service_credential)
spark.conf.set("fs.azure.account.oauth2.client.endpoint.<storage-account>.dfs.core.windows.net", "https://login.microsoftonline.com/<directory-id>/oauth2/token")you can check out below two links:
https://docs.databricks.com/external-data/azure-storage.html
https://docs.databricks.com/_static/notebooks/adls-gen2-service-principal.html
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2023 07:33 AM
Please mount ADLS storage as described here:
https://community.databricks.com/s/feed/0D53f00001eQGOHCA4
And then write pandas to excel to that directory.
df.to_excel("output.xlsx")
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-02-2023 01:25 PM
Hi @Hubert Dudek,
Pandas API doesn't support abfss protocol.
You have three options:
- If you need to use pandas, you can write the excel to the local file system (dbfs) and then move it to ABFSS (for example with dbutils)
- Write as csv directly in abfss with the Spark API (without using pandas)
- Write the dataframe as excel with the Spark API directly in abfss with a library like https://github.com/crealytics/spark-excel. (without using pandas)
Thanks.
Fernando Arribas
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2023 12:57 AM
But once you mount it, you can write as it is visible as a dbfs directory.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2023 05:16 AM
Have you tried writing to the local file system (for example, in the path /databricks/...)
Anyway, i recommend you to tyr writing with Spark (without dataframes). Pandas without additional libraries, doesn't distribute and with high volumes you will have memory problems, performance problems...
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2023 05:17 AM
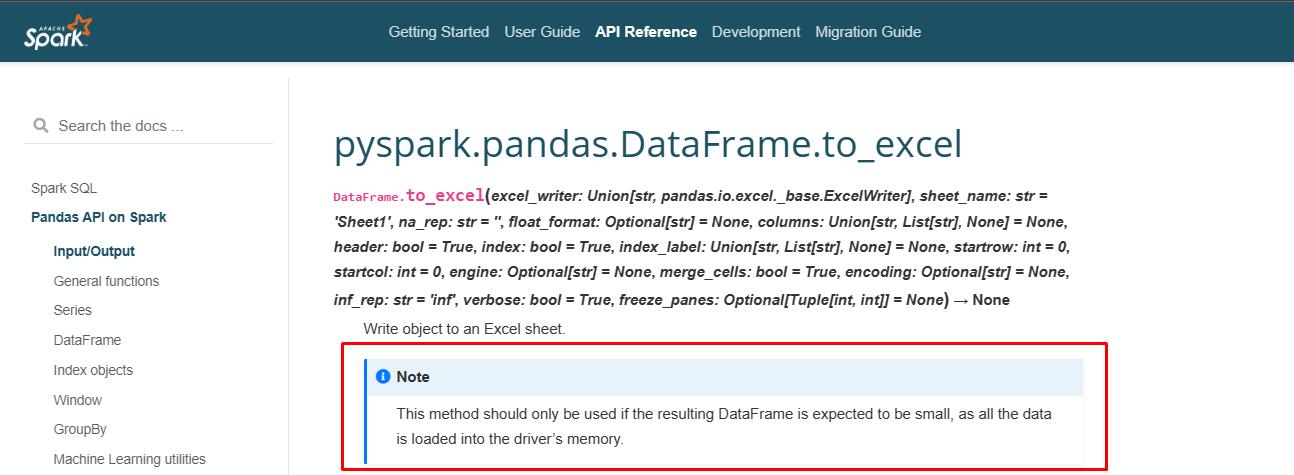
It is enough to use pandas on a spark, so it is distributed. Additionally, pandas have the to_excel method, but spark data-frames do not.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2023 05:51 AM
I'm not sure about that. When you call the function to_excel all the data is loaded into the driver (as if you were doing a collect). So, the writing is not distributed and you can have memory and performance problems as I mentioned.

Try writing with this library:
https://github.com/crealytics/spark-excel
Example (https://github.com/crealytics/spark-excel/issues/134#issuecomment-517696354):
df.write
.format("com.crealytics.spark.excel")
.save("test.xlsx")
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-04-2023 01:55 PM
Under the general scenario this shouldn't be an issue since an Excel file can only handle a little over a million rows anyway. Saying that, your statement that this should be written to dbfs and use dbutils to move the file to abfs should be the accepted answer.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-03-2023 05:22 AM
i done that, but in spark df not able to add bg color and cell alignment based on values in excel sheet
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-05-2024 05:54 PM
how can I know the path in dbfs where the file is written?
from the Workspace I have tried with
path
URLpath
Announcements





{kind=link}
Related Content
- Can't run SQL on my cluster in Warehousing & Analytics
- Spark Structured Streaming Timeout Waiting for KafkaAdminClient Node Assignment on Amazon MSK in Data Engineering
- df.isEmpty() and df.fillna(0).isEmpty() throws error in Data Engineering
- Not able to access Table_tags in Databricks Apps: in Data Engineering
- Connection reset by peer logging when importing custom package in Data Engineering