Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: How to merge small parquet files into a singl...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-03-2021 12:58 PM
I have thousands of parquet files having same schema and each has 1 or more records. But reading with spark these files is very very slow.
I want to know if there is any solution how to merge the files before reading them with spark?
Or is there any other option in Azure Data Factory to merge these files(though the merge option exists for text files).
Labels:
- Labels:
-
Small Parquet Files


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-08-2021 03:42 PM
Hi @nafri A ,
I don't think there is a solution to merge the files before readying them in Spark. Like @Werner Stinckens said, you will need to read all the files and saved them as Delta lake. Once all the files are written as Delta lake, then you can do optimized to compact the files.
8 REPLIES 8
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-03-2021 03:47 PM
Hello, @nafri A. Welcome and thank you for your question. My name is Piper and I'm a community moderator for Databricks. Let's see if the community has any solutions or ideas. If not, we'll circle back around.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-04-2021 05:14 AM
if they are already written, you have to bite the apple and read them (with spark/databricks or ADF data flow). Then you can coalesce/repartition them and write the merged files back to the data lake.
Another option is by using delta lake, using MERGE statement (incoming data is merged in the existing).
Delta lake handles the partitioning. But still: you have to initially read all those small files first and write them to delta lake.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-04-2021 05:26 AM
Sometimes for such a simple data transformation like merging I use indeed Data Factory but as it is written on top of Spark it will be similar.
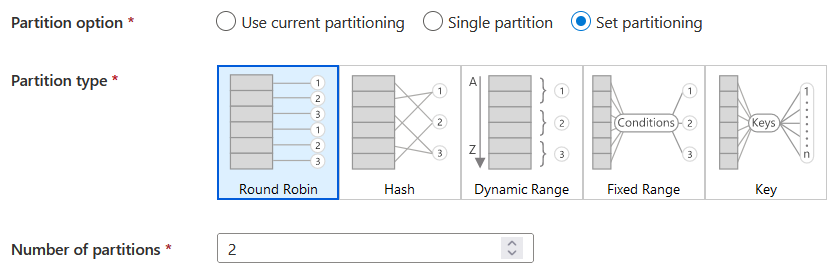
More workers and parallel read jobs will help. For example in data factory you can use "Run in parallel" and "Set partitioning" options.
In databricks it will be faster with autoload (you can always use stream trigger once to run as batch) https://docs.microsoft.com/en-us/azure/databricks/spark/latest/structured-streaming/auto-loader-gen2
Setting schema instead of inferSchema will help to avoid double scan.
Always partitioning is a key so files will be loaded from different directories in parallel:

My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-08-2021 03:42 PM
Hi @nafri A ,
I don't think there is a solution to merge the files before readying them in Spark. Like @Werner Stinckens said, you will need to read all the files and saved them as Delta lake. Once all the files are written as Delta lake, then you can do optimized to compact the files.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-10-2021 04:08 AM
Hi @nafri A
I second what @Jose Gonzalez suggested. You can first read in spark and convert it into Delta lake, after conversion, you can run OPTIMIZE command which will coalesce all the small files into a bigger sizes. Then you can just convert it back to parquet from Delta if you want. Below are the commands that will be useful:
Convert Parquet to Delta lake:
%sql
-- Convert non partitioned parquet table at path '<path-to-table>'
CONVERT TO DELTA parquet.`<path-to-table>`
-- Convert partitioned Parquet table at path '<path-to-table>' and partitioned by integer columns named 'part' and 'part2'
CONVERT TO DELTA parquet.`<path-to-table>` PARTITIONED BY (part int, part2 int)Optimize Delta Lake:
%sql
-- Optimize our Delta table
OPTIMIZE delta.`/table_delta/`Convert back to Parquet:
- If you have performed Delta Lake operations that can change the data files (for example, delete or merge), run VACUUM with a retention of 0 hours to delete all data files that do not belong to the latest version of the table.
- Delete the _delta_log directory in the table directory.
Note: This will be a one time process to compact small files into bigger files
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-18-2021 10:05 AM
Hi @nafri A ,
Did any of our response helped to solve this issue? would you be happy to mark the answer as best so that others can quickly find the solution?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-19-2024 11:47 AM
Give [*joinem*](https://github.com/mmore500/joinem) a try, available via PyPi: `python3 -m pip install joinem`.
*joinem* provides a CLI for fast, flexbile concatenation of tabular data using [polars](https://pola.rs).
I/O is *lazily streamed* in order to give good performance when **working with numerous, large files**.
## Example Usage
Pass input files via stdin and output file as an argument.
ls -1 path/to/*.parquet | python3 -m joinem out.parquetYou can add the `--progress` flag to get a progress bar.
## No-install Containerized Interface
If you are working in a HPC environment, *joinem* can also be conveniently used via [singularity/apptainer](https://apptainer.org).
ls -1 *.pqt | singularity run docker://ghcr.io/mmore500/joinem out.pqt## Further Information
*joinem* is also compatible with CSV, JSON, and feather file types.
See the project's [README](https://github.com/mmore500/joinem/) for more usage examples and a full command-line interface API listing.
*disclosure*: I am the library author of *joinem*.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-17-2024 11:01 AM
We can combine all these small parquet files into single file using optimize command..
Optimize delta_table_name
Announcements





{kind=link}
Related Content
- Integration patterns with Oracle database in Administration & Architecture
- Auto Loader with ignoreMissingFiles and useManagedFileEvents fails on Classic Compute in Data Engineering
- Querying CDF on a Delta-Sharing table after data type change in the Table (INT to DECIMAL) in Data Engineering
- Is there a Sample Java Program using Databricks Connect Library to query a table In the Free Editio? in Warehousing & Analytics
- What is the best way to use Unity catalog with medallion architecture using ADLS2 in Administration & Architecture