Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- How to merge two data frames column-wise in Apache...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
How to merge two data frames column-wise in Apache Spark
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-13-2016 01:33 PM
I have the following two data frames which have just one column each and have exact same number of rows. How do I merge them so that I get a new data frame which has the two columns and all rows from both the data frames. For example,
df1:
+-----+
| ColA|
+-----+
| 1|
| 2|
| 3|
| 4|
+-----+
df2:
+-----+
| ColB|
+-----+
| 5|
| 6|
| 7|
| 8|
+-----+
I want the result of the merge to be
df3:
+-----+-----+
| ColA| ColB|
+-----+-----+
| 1| 5|
| 2| 6|
| 3| 7|
| 4| 8|
+-----+-----+
I don't quite see how I can do this with the join method because there is only one column and joining without any condition will create a cartesian join between the two columns. Is there a direct SPARK Data Frame API call to do this? In R Data Frames, I see that there a merge function to merge two data frames. However, I don't know if it is similar to join.
Thanks,
Bhaskar
Labels:
- Labels:
-
Dataframe
-
Spark--dataframe


9 REPLIES 9
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-11-2016 01:11 PM
Hi All , Even I am working on the same Problem ? Any findings ? Thanks !
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-15-2017 02:01 PM
@bhosskie and @Govind89
Think what is asked is to merge all columns, one way could be to create monotonically_increasing_id() column, only if each of the dataframes are exactly the same number of rows, then joining on the ids. The number of columns in each dataframe can be different.
from pyspark.sql.functions import monotonically_increasing_id
df1 = sqlContext.createDataFrame([("foo", "bar","too","aaa"), ("bar", "bar","aaa","foo"), ("aaa", "bbb","ccc","ddd")], ("k", "K" ,"v" ,"V"))
df2 = sqlContext.createDataFrame([("aaa", "bbb","ddd"), ("www", "eee","rrr"), ("jjj", "rrr","www")], ("m", "M" ,"n"))
df1 = df1.withColumn("id", monotonically_increasing_id())
df2 = df2.withColumn("id", monotonically_increasing_id())
df1.show()
df2.show()
df3 = df2.join(df1, "id", "outer").drop("id")
df3.show()
Gives output of the columns merged, although the order is reversed in the rows displayed.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-18-2018 04:18 AM
Thanks! This seems to work for me; although I was nervous about using monotonically_increasing_id() because the ids could be different for corresponding rows in the two dataframes if any parts of them were generated in different partitions. But I guess if df2 is generated from df1 the chances of that happening in practice are fairly low...? Anyway, I use a "left_outer" join to make sure I keep the rows I want in the dataframe I consider most important.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2018 06:27 AM
I have the same problem. Is there any solution without using join.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2019 09:09 AM
hi
Thanks for the data at the trash bag cover. I did manage to discover some clean ones that could do the trick, however, they're very extensive so will discern a few manners of lowering the diameter. If I positioned elastic around them, it will compress the lure too so welcome any greater tips. The lure itself has been operating wonderfully! I'm capturing a few butterflies I have not seen in years and I scored a fairly massive moth too. I'm having two problems though: flies and hornets. I even have zippers along the side, however, the bugs generally tend to want to exit the top and not the aspect. I assume I'm going to need to add zippers to the top coming at one another from angles so that after both are unzipped, I can just fold again the cloth. Since this can take some doing, perhaps you could propose a higher way? Thanks once more! Read greater at
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-27-2019 09:10 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
10-09-2019 04:11 AM
Hi, if you are looking for the answer for “Why My Brother Printer is Offline“? There could be many reasons for receiving message Brother Printer is offline. Follow the easy steps in the article to resolve Brother Printer Offline issues.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-01-2020 01:35 AM
I have the same problem
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-16-2020 09:36 AM
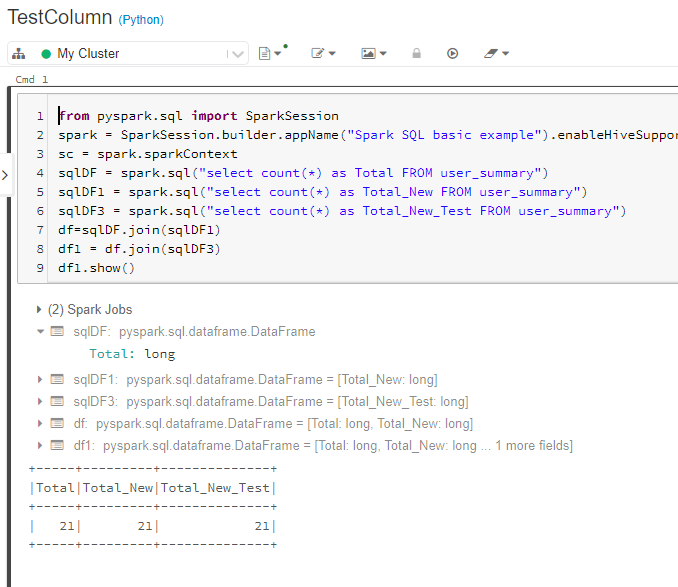
@bhosskie
from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("Spark SQL basic example").enableHiveSupport().getOrCreate()
sc = spark.sparkContext
sqlDF1 = spark.sql("select count(*) as Total FROM user_summary")
sqlDF2 = spark.sql("select count(*) as Total_New FROM user_summary")
df=sqlDF1.join(sqlDF2)
df.show()

Announcements





{kind=link}
Related Content
- AnalysisException: [UNRESOLVED_ROUTINE] Cannot resolve routine `=` in Data Engineering
- Apache Spark 4.2 is officially here! Key architectural updates for AI-Native & Governed Platforms in Data Engineering
- ALTER Not Working in Databricks for external Table. in Data Engineering
- DB runtime 18 in Administration & Architecture
- Getting error hadoop_azure_shaded.com.microsoft.azure.storage.StorageException: The specified blob d in Data Engineering