How to process files from the internet in databricks?
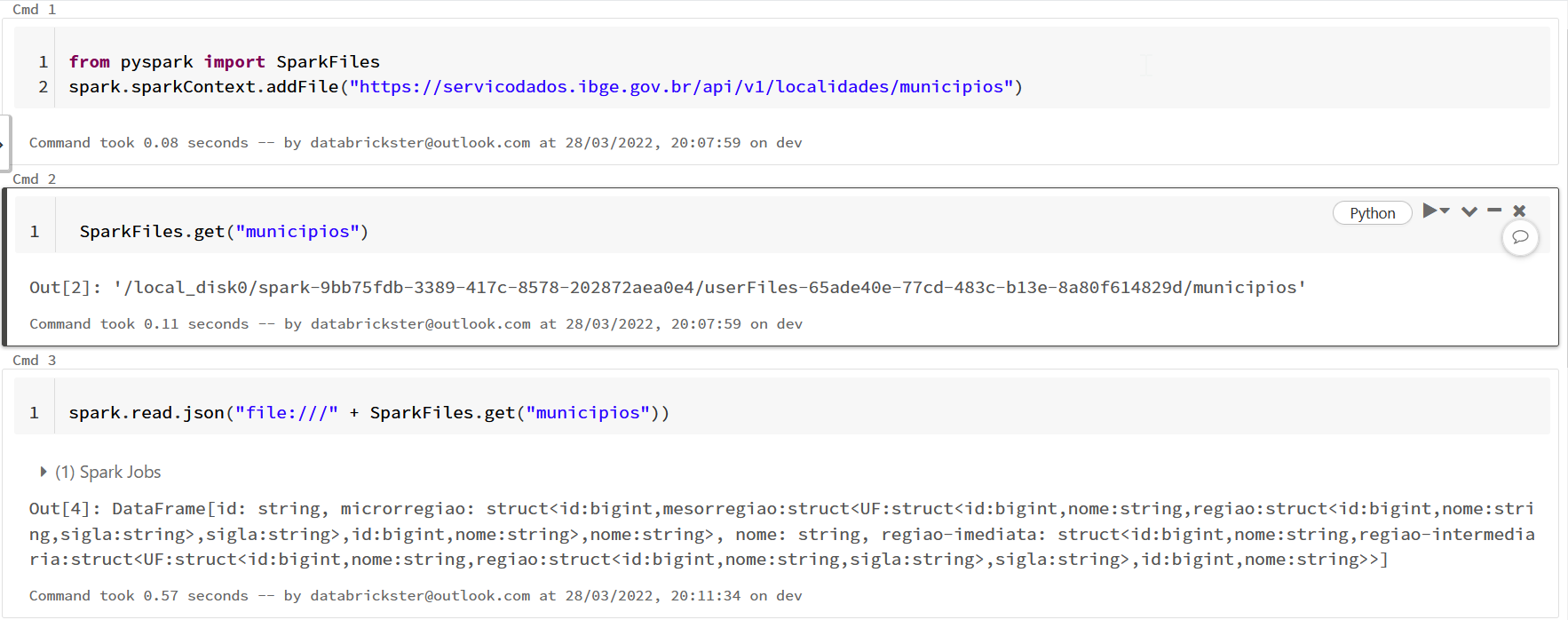
"spark.sparkContext.addFile" download file to HDFS directory. "SparkFiles.get" return the path and the name. However, as Databricks use the DBFS file system, we need to add the "file:///" prefix to get files from the legacy HDFS system.

My blog: https://databrickster.medium.com/







{kind=link}