Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- How to read JSON files embedded in a list of lists...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-16-2022 05:24 AM
Hello
I am trying to read this JSON file but didn't succeed


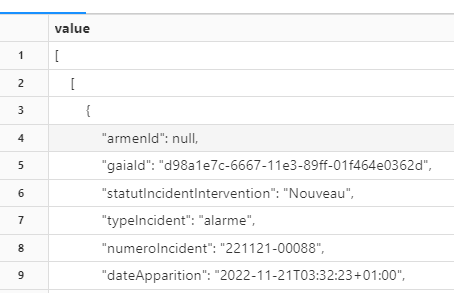
You can see the head of the file, JSON inside a list of lists. Any idea how to read this file?

Labels:
- Labels:
-
Jsonfile


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2022 05:51 AM
Here is my solution, I am sure it can be optimized
import json
data=[]
with open(path_to_json_file, 'r') as f:
data.extend(json.load(f))
df = spark.createDataFrame(data[0], schema=schema)✌️
5 REPLIES 5
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-17-2022 11:31 PM
Hi @Amine HADJ-YOUCEF , The data sources are limited, please refer: https://spark.apache.org/docs/latest/sql-data-sources-json.html#data-source-option
Also, https://docs.databricks.com/external-data/json.html
Please let us know if this helps.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2022 05:04 AM
Thank you for sharing,
these links do not address the exact problem I am facing
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2022 05:06 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-21-2022 05:51 AM
Here is my solution, I am sure it can be optimized
import json
data=[]
with open(path_to_json_file, 'r') as f:
data.extend(json.load(f))
df = spark.createDataFrame(data[0], schema=schema)✌️
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-12-2024 10:32 PM - edited 09-12-2024 10:33 PM
The correct way to do this without using open, which will work only with local/mounted files is to read the files as binaryfile and then you will get the entire json string on each row, from there you can use from_json() and explode() to extract the objects inside your array (I assume the outer array is just wrapping the other array, if you have records inside an array of arrays, then you would use explode() twice.
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Databricks unable to list ADLS folder and files in Data Engineering
- Lakeventory: Automated Asset Discovery for Databricks Workspaces in Administration & Architecture
- Best pattern for ingesting data from hundreds of separate ADLS Gen2 containers into Databricks? in Data Engineering
- DLT Autoloader schemaHints from JSON file instead of inline list? in Data Engineering
- Migrating from directory-listing to Autoloader Managed File events in Data Engineering