Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: how to read schema from text file stored in cl...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
how to read schema from text file stored in cloud storage
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-23-2019 11:48 PM
I have file a.csv or a.parquet while creating data frame reading we can explictly define schema with struct type. instead of write the schema in the notebook want to create schema lets say for all my csv i have one schema like csv_schema and stored in cloud storage. if any addition or deletion i will do that in csv_schema file separately.
In notebook when creating data frame during reading file want to pass this schema which stored in separate file .Please suggest if we can write any function in python or other idea to automate schema creation and addition in data frame for different file systemSo its like, i have schema file a.schema where i have the schema definition for all the parquet file/any file its generic. kind of like
a.schema text file contains below details
schema1=StructType([StructField("x1", StringType(), True),StructField("Name", StringType(), True),StructField("PRICE", DoubleType(), True)])
read the a.schema from storage in notebook create the required schema which need to pass to dataframe.
df=spark.read.schema(generic schema).parquet ..
Labels:


7 REPLIES 7
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-24-2019 12:27 AM
Hi @sani nanda,
Please follow the below steps,
- Read the schema file as a CSV, setting header to true. This will give an empty dataframe but with the correct header.
- Extract the column names from that schema file.
column_names = spark.read.option("header",true).csv(schemafile).columns- Now read the datafile and change the default column names to the ones in the schema dataframe.
df = spark.read.option("header", "false").option("inferSchema", "true").csv(datafile).toDF(column_names: _*)Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-24-2019 03:22 AM
Hi @shyamspr
Thanks for sharing the answer. Actually i have tried with the approach like taking the header from raw filename and then adding those again.But the issue is want to explicitly change the data type as required without reading for inferring schema .
is there any way can add data type along with column name programmatically like in case where we have 30+ columns.
that's why trying to have schema file separately where we have column name and data type in list or structfiled.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-24-2019 04:23 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
09-24-2019 08:14 AM
@shyamspr,Thanks for looking but as said both scenarios like we need to add the column data type explicitly with in notebook, consider 30 to 40+ columns .Its not reusable each notebook need to add the schema .
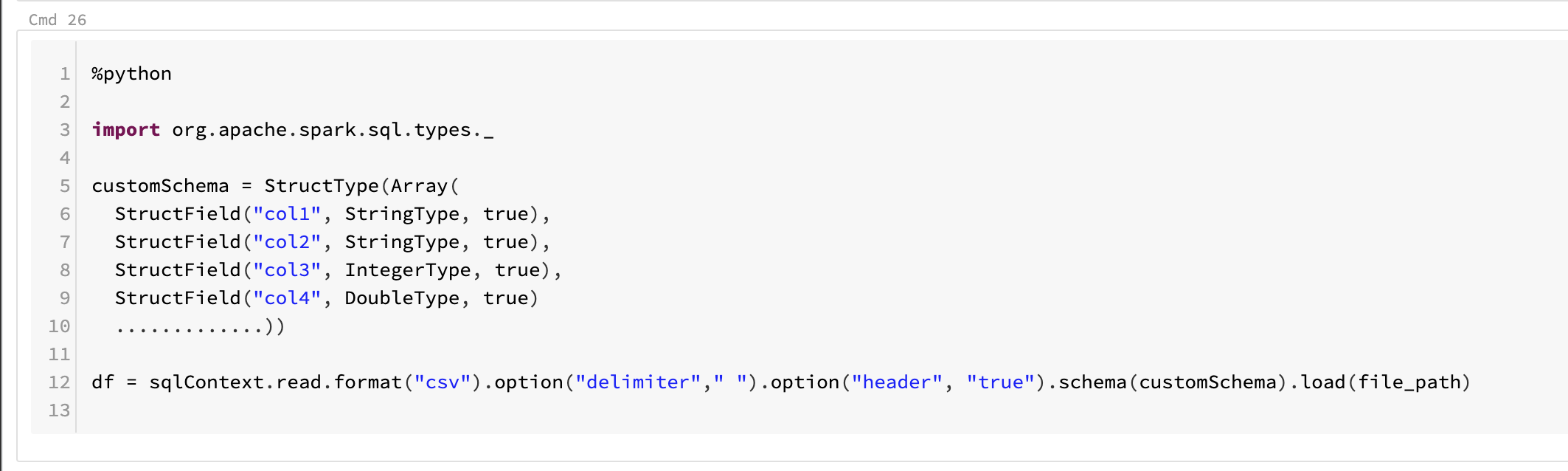
As you updated say like the custom schema structure, am storing that in one file custom_schema.txt .was trying to apply that schema from that file custom_schema.txt ,where we have the Struct type and fields defined, during data read from the file path and dataframe creation
but not able to make it. So was thinking if any python function or any utility can do help to form the reusable code like read the schema definition from file and during data frame we can use same.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-15-2020 12:26 AM
@sunil nanda
I wrote this code below read schema from my git controlled schema library on Azure storage. it converts a spark json schema in a file to a spark schem
This is an example of a schema with 1 column:
{
"type": "struct",
"fields": [
{
"name": "Data",
"type": "string",
"nullable": true,
"metadata": {}
}
]
}
Don't type this out. You can get it initially during development by loading the data inferred, copy it out into a file, pretty print it and then review it and tweak to the desired schema, put it in VS code git project and deploy it to the lake.
To get the schema out of an inferred df do this:
df.schema.jsonCode to read the schema from the attached lake storage. The path can be azure or s3 storage protocol paths but you have to mount it first in the session or use passthrough... don't use global mounts, that's really bad security practice and incredibly lazy!!
def loadSparkSchema(path:String) =
{
if (path==null || path.isEmpty()) null:StructType
try
{
var file = ""
val filedf = spark.read
.option("multiLine", true)
.option("mode", "PERMISSIVE")
.option("delimiter", "\n")
.csv(path)
for(line <- filedf.collect())
{
file = file + line(0)
}
Try(DataType.fromJson(file).asInstanceOf[StructType])
match {
case Success(s) => s
case Failure(f) => {
logError(s"Failed to parse spark schema from json file at ${path}\n ${f}")
}
}
}
catch
{
case e: Exception =>
logError(s"Failed to parse spark schema from json file at ${path}\n ${e.getMessage()}")
}
}
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-12-2021 05:56 AM
Python Function:
def read_schema(arg):
d_types = {
"varchar":StringType(),
"integer":IntegerType(),
"timestamp":TimestampType(),
"double":DoubleType(),
"date":DateType(),
"decimal":DecimalType()
}
split_values= arg.split(",")
sch= StructType()
for i in split_values:
x=i.split("|")
sch.add(x[0],d_types[x[1]],True)
return sch
Sample schema Input file:
id|integer,
cust_nr|varchar,
bus_name|varchar,
bus_tym|varchar,
bus_desciprion|varchar
The code need to be implemented in the pyspark job:
textRDD1 = sc.textFile("Schema_file.txt")
llist = textRDD1.collect()
listToStr = ''.join([str(elem) for elem in llist])
sch = read_schema(listToStr)
df= spark.read.csv(path='Table_PATH',schema=sch, header=False, sep='|')
df.show()
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-14-2021 02:28 AM
@shyampsr big thanks, was searching for the solution almost 3 hours 😞
_https://luckycanadian.com/
Announcements





{kind=link}
Related Content
- oreign Iceberg tables via HMS federation fail with browse_only_table on all compute — request Public in Data Engineering
- Enterprise Unity Catalog RBAC model in Databricks in Data Governance
- Ingesting data from a SharePoint Excel file with two worksheets in one pipeline in Data Engineering
- Lakeflow Connect & Community Connectors - 403 Errors + What is the compute? in Data Engineering
- Stop Translating Alteryx Boxes - A Lakebridge-assisted, test-driven migration to Azure Databricks in Data Engineering