I have a delta table created by:
%sql
CREATE TABLE IF NOT EXISTS dev.bronze.test_map (
id INT,
table_updates MAP<STRING, TIMESTAMP>,
CONSTRAINT test_map_pk PRIMARY KEY(id)
) USING DELTA
LOCATION "abfss://bronze@Table Path"
With initial values:
INSERT INTO dev.bronze.test_map
VALUES (1, null),
(2, null),
(3, null);
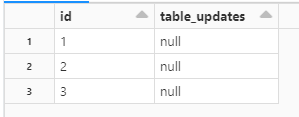
Note that there is no value in column "table_updates".

After processing other tables in our platform, I have table updates info as a python dictionary like below:
table_updates_id1 =
{'id1_table_1': datetime.datetime(2023, 3, 26, 4, 33, 22, 323000),
'id1_table_2': datetime.datetime(2023, 3, 26, 4, 33, 22, 323000)}

Now, I want to update the value of column "table_update " where id=1 using SQL UPDATE command (note that I want to update the table not dataframe).
I tried different methods but failed.
1st trial:
spark.sql(f"""
UPDATE dev.bronze.test_map
SET
table_updates = map({table_updates_id1})
WHERE
id = 1
""")
Error:

2nd trial:
spark.sql(f"""
UPDATE dev.bronze.test_map
SET
table_updates = map('{','.join([f'{k},{v}' for k,v in table_updates_id1.items()])}')
WHERE
id = 1
""")
Error:

Any idea how to solve this issue? Thanks.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}