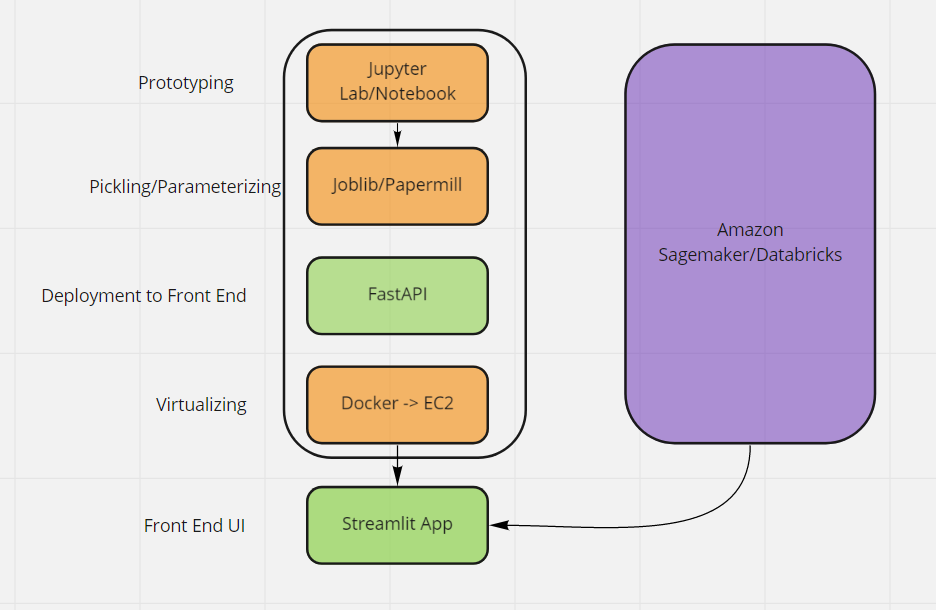
Hi all, thank you for taking the time to attend to my post. A background to preface, my team and I have been prototyping an ML model that we would like to push into the production and deployment phase. We have been prototyping on Jupyter Notebooks but are trying to figure out what tools and platforms we may require.
I'm by no means an expert in data architecture and was hoping someone could shed some light. In the diagram attached, is my understanding of it thus far (implying that something like Databricks and Sagemaker is an all in one platform) However, I'm not sure if they have functionalities like:
- version control
- parameterization of the notebooks
- templatizing notebooks

Hope to hear back! And participate in an active discussion! Thank you so much!







{kind=link}