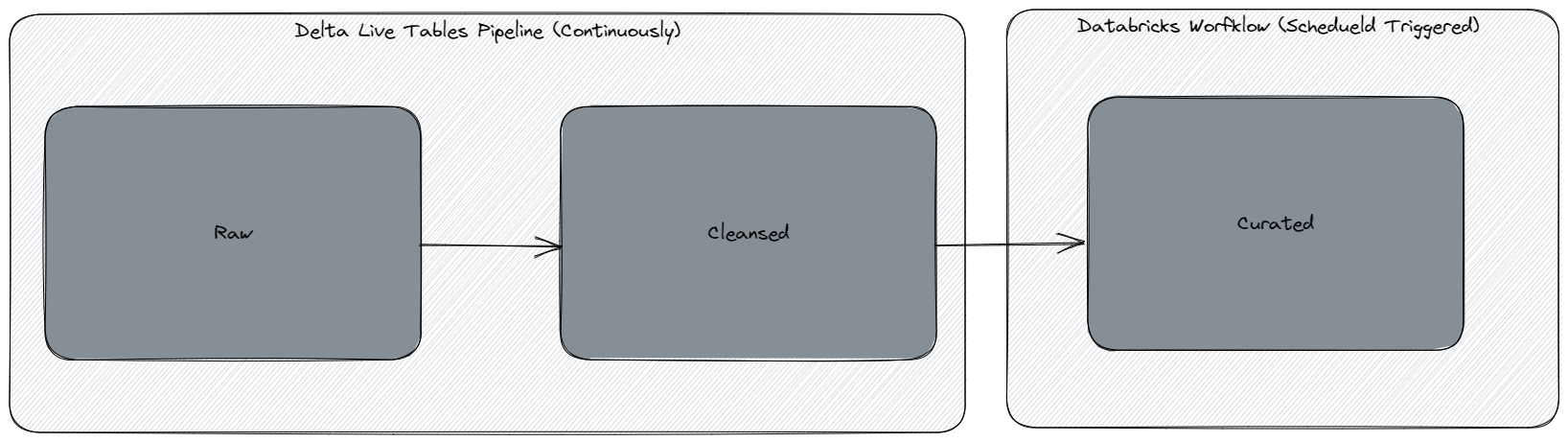
Ok, i'll try an add additional details. Firstly: The diagram below shows our current dataflow:

Our raw table is defined as such:
TABLES = ['table1','table2']
def generate_tables(table_name):
@dlt.table(
name=f'raw_{table_name}',
table_properties = {
'quality': 'bronze',
}
)
def create_table():
return (
spark.readStream.format('cloudfiles')
.option('cloudFiles.format', 'parquet')
.option('pathGlobfilter', '*.parquet')
.option("cloudFiles.useNotifications", "true")
.option('cloudFiles.clientId', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-client-id'))
.option('cloudFiles.clientSecret', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-client-secret'))
.option('cloudFiles.connectionString', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-connection-string'))
.option('cloudFiles.resourceGroup', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-resource-group'))
.option('cloudFiles.subscriptionId', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-subscription-id'))
.option('cloudFiles.tenantId', dbutils.secrets.get(SECRET_SCOPE, 'db-autoloader-tenant-id'))
.option('mergeSchema', 'true')
.load(f'dbfs:/mnt/raw/{table_name}/*.parquet')
.withColumn('Meta_SourceFile', input_file_name())
.withColumn('Meta_IngestionTS', current_timestamp())
)
for t in tables:
generate_tables(t)
And our cleansed (SCD2) is created as such:
def generate_scd_tables(table_name, keys, seq_col, exc_cols, scd_type):
dlt.create_streaming_live_table(f'cleansed_{table_name}_scd{scd_type}',
table_properties = {
'delta.enableChangeDataFeed': 'true',
'pipelines.reset.allowed': 'false',
'quality': 'silver'
})
dlt.apply_changes(
target = f'cleansed_{table_name}_scd{scd_type}',
source = f'raw_{table_name}',
keys = keys,
sequence_by = col(seq_col),
track_history_except_column_list = exc_cols, #Input must be given as a list, .e.g ["Id"]
stored_as_scd_type = scd_type
)
generate_scd_tables(table_name='tabel1', keys=['Id'], seq_col='Meta_IngestionTS', exc_cols=['id', 'Meta_IngestionTS', 'Meta_SourceFile'], scd_type=2)
Due to the volume of data we receive, we would like to truncate the raw table periodically. However, if we either delete or truncate the raw table as of now, the whole delta live pipeline will fail giving the following eror message: .from streaming source at version 191. This is currently not supported. If you'd like to ignore deletes, set the option 'ignoreDeletes' to 'true'
But how do we set that option? We have tried both on raw and SCD2 without any success. I would rather not introduce a temporary table as you suggest, as that table will not be realtime.







{kind=link}