Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Is there some form of enablement required to u...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-25-2022 02:02 PM
I'm trying to use delta live tables, but if I import even the example notebooks I get a warning saying `ModuleNotFoundError: No module named 'dlt'`. If I try and install via pip it attempts to install a deep learning framework of some sort.
I checked the requirements document and don't immediately see a runtime requirement; am I missing something? Is there something else I need to do to use this feature?
Labels:
- Labels:
-
Delta Live Tables
-
DLT


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-27-2022 04:07 PM
Yes, you will get that error when you run the notebook.
Follow the below steps-
- On the Databricks notebook left panel, select 'Jobs'

- Select 'Delta Live Tables'

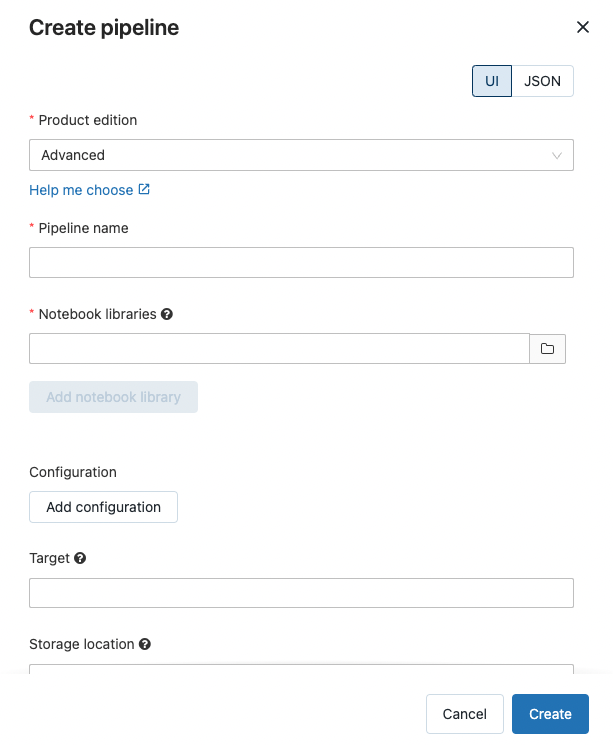
- Select 'Create Pipeline'

- Fill in the details- Pipeline name and in Notebook Libraries: Point to your notebook where you have the dlt code.

- Click on 'Start' on top right corner
- This will start the pipeline, populate the tables and give a graphical representation.
- NOTE: Make sure in your notebook, you attach the cluster
https://docs.databricks.com/data-engineering/delta-live-tables/delta-live-tables-quickstart.html
6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-27-2022 04:07 PM
Yes, you will get that error when you run the notebook.
Follow the below steps-
- On the Databricks notebook left panel, select 'Jobs'
- Select 'Delta Live Tables'
- Select 'Create Pipeline'
- Fill in the details- Pipeline name and in Notebook Libraries: Point to your notebook where you have the dlt code.
- Click on 'Start' on top right corner
- This will start the pipeline, populate the tables and give a graphical representation.
- NOTE: Make sure in your notebook, you attach the cluster
https://docs.databricks.com/data-engineering/delta-live-tables/delta-live-tables-quickstart.html
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-29-2022 02:31 PM
Thanks a lot for sharing this great example
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-28-2022 01:17 AM
This error is so annoying... Is it going to be fixed or is there any workaround to avoid it?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-28-2022 10:01 AM
Well you are not supposed to run the notebook, you just need to create tables Delta Live Tables in the notebook and attach a cluster. After you have done that, you need to go to jobs to start the pipeline. The pipeline gathers resources from the notebook, initializes it, sets up tables and renders the graph. Delta live Tables is of type orchestration.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-28-2022 01:07 PM
Got it. That helps, thanks.
That could maybe be clearer in the documentation; it wasn't immediately clear to me that I couldn't run this outside a normal notebook environment. From the documentation it sounded like I could develop that way and then set up the DLT environment only for use.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-01-2022 10:10 AM
Here's the solution I came up with... Replace `import dlt` at the top of your first cell with the following:
try:
import dlt # When run in a pipeline, this package will exist (no way to import it here)
except ImportError:
class dlt: # "Mock" the dlt class so that we can syntax check the rest of our python in the databricks notebook editor
def table(comment, **options): # Mock the @dlt.table attribute so that it is seen as syntactically valid below
def _(f):
pass
return _; Further mocking may be required depending on how many features from the dlt class you use, but you get the gist.
You can "catch" the import error and mock out a dlt class sufficiently that the rest of your code can be checked. This slightly improves the developer experience until you get a chance to actually run it in a pipeline.
As many have noted, the special "dlt" library isn't "available" when running your python code from the databricks notebook editor, only when running it from a pipeline (which means you lose out on being able to easily check your code's syntax before attempting to run it)
You also can't "%pip install" this library, because it isn't a public package, and the "dlt" package out there has nothing to do with Databricks.
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Seek for Help: enable/disable BROWSE privilege on specific tables, possible or not? in Data Governance
- Import Data from Databricks to SQL Server in Data Engineering
- Does enabling Change Data Feed on a Delta table affect OPTIMIZE and ZORDER performance? in Data Engineering
- Materialized view creation fails in Data Engineering
- matching sas proc survey means for quantiles in databricks in Data Engineering