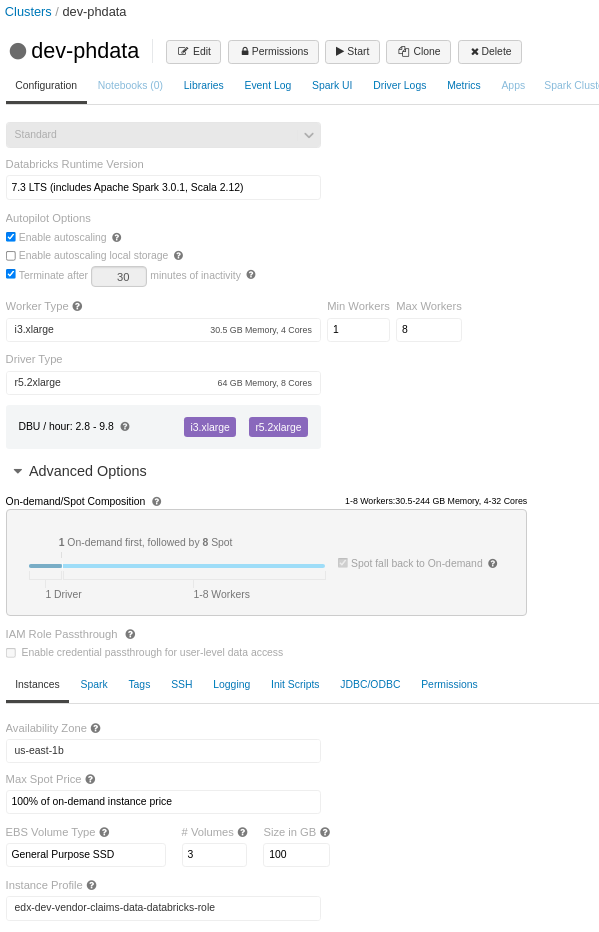
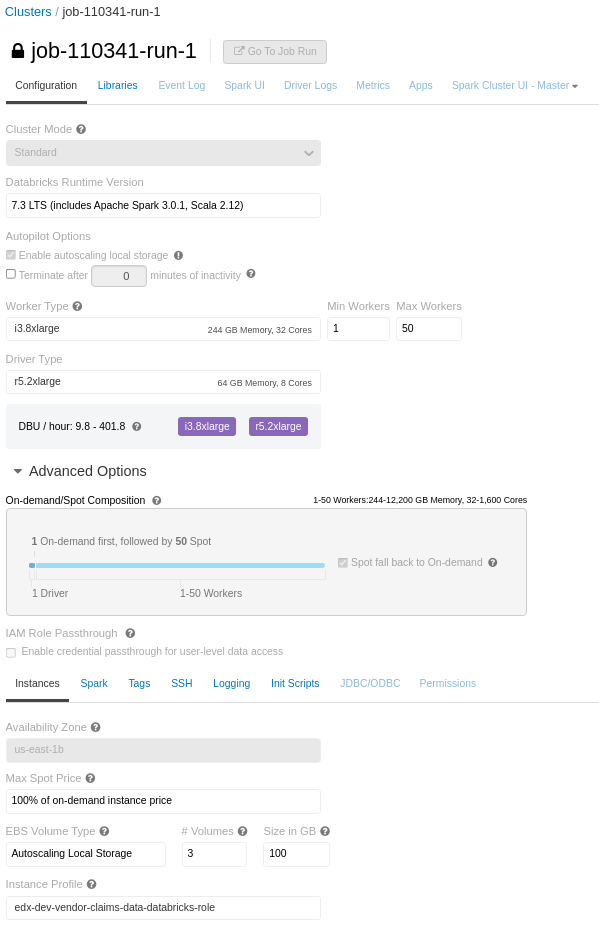
I have a notebook with many join and few persist operations (which runs fine on all-purpose-cluster (with worker nodes - i3.xlarge and autoscale enabled), but the same notebook failing in job-cluster with the same cluster definition (to be frank the job-cluster has even better worker nodes - i3.8xlarge)
Cluster Conf:

 Spark Conf:
Spark Conf:
spark.databricks.delta.optimizeWrite.enabled true
spark.databricks.adaptive.autoOptimizedShuffle.enabled true
Error:
Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: ShuffleMapStage 69 (sql at command-3296064203992845:4) has failed the maximum allowable number of times: 4. Most recent failure reason: org.apache.spark.shuffle.FetchFailedException: Connection reset by peer at org.apache.spark.storage.ShuffleBlockFetcherIterator.throwFetchFailedException(ShuffleBlockFetcherIterator.scala:749) at org.apache.spark.storage.ShuffleBlockFetcherIterator.next(ShuffleBlockFetcherIterator.scala:662) at org.apache.spark.storage.ShuffleBlockFetcherIterator.next(ShuffleBlockFetcherIterator.scala:69) at org.apache.spark.util.CompletionIterator.next(CompletionIterator.scala:29) at scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:484) at scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:490) at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458) at org.apache.spark.util.CompletionIterator.hasNext(CompletionIterator.scala:31) at org.apache.spark.InterruptibleIterator.hasNext(InterruptibleIterator.scala:37) at scala.collection.Iterator$$anon$10.hasNext(Iterator.scala:458) at org.apache.spark.sql.execution.UnsafeExternalRowSorter.sort(UnsafeExternalRowSorter.java:240) at org.apache.spark.sql.execution.SortExec$$anon$2.sortedIterator(SortExec.scala:133) at org.apache.spark.sql.execution.SortExec$$anon$2.hasNext(SortExec.scala:147) at org.apache.spark.sql.execution.RowIteratorFromScala.advanceNext(RowIterator.scala:83) at org.apache.spark.sql.execution.joins.SortMergeJoinScanner.advancedBufferedToRowWithNullFreeJoinKey(SortMergeJoinExec.scala:950) at org.apache.spark.sql.execution.joins.SortMergeJoinScanner.<init>(SortMergeJoinExec.scala:820) at org.apache.spark.sql.execution.joins.SortMergeJoinExec.$anonfun$doExecute$1(SortMergeJoinExec.scala:258) at org.apache.spark.rdd.ZippedPartitionsRDD2.compute(ZippedPartitionsRDD.scala:101) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:356) at org.apache.spark.rdd.RDD.iterator(RDD.scala:320) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:60) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:356) at org.apache.spark.rdd.RDD.iterator(RDD.scala:320) at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:60) at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:356) at org.apache.spark.rdd.RDD.iterator(RDD.scala:320) at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52) at org.apache.spark.scheduler.Task.doRunTask(Task.scala:144) at org.apache.spark.scheduler.Task.run(Task.scala:117) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$9(Executor.scala:655) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1581) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:658) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: java.io.IOException: Connection reset by peer at sun.nio.ch.FileDispatcherImpl.read0(Native Method) at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39) at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223) at sun.nio.ch.IOUtil.read(IOUtil.java:192) at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:379) at io.netty.buffer.PooledByteBuf.setBytes(PooledByteBuf.java:253) at io.netty.buffer.AbstractByteBuf.writeBytes(AbstractByteBuf.java:1133) at io.netty.channel.socket.nio.NioSocketChannel.doReadBytes(NioSocketChannel.java:350) at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:148) at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:714) at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:650) at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:576) at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:493) at io.netty.util.concurrent.SingleThreadEventExecutor$4.run(SingleThreadEventExecutor.java:989) at io.netty.util.internal.ThreadExecutorMap$2.run(ThreadExecutorMap.java:74) at io.netty.util.concurrent.FastThreadLocalRunnable.run(FastThreadLocalRunnable.java:30) ... 1 more
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2519)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2466)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2460)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2460)
at org.apache.spark.scheduler.DAGScheduler.handleTaskCompletion(DAGScheduler.scala:2050)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2718)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2668)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2656)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
Note: If you also notice the EBS Volume Type in job-cluster is displayed as Autoscaling Local Storage instead of General Purpose SSD, as I have set it as General Purpose SSD







{kind=link}
{kind=link}