Hi @AanchalSoni,
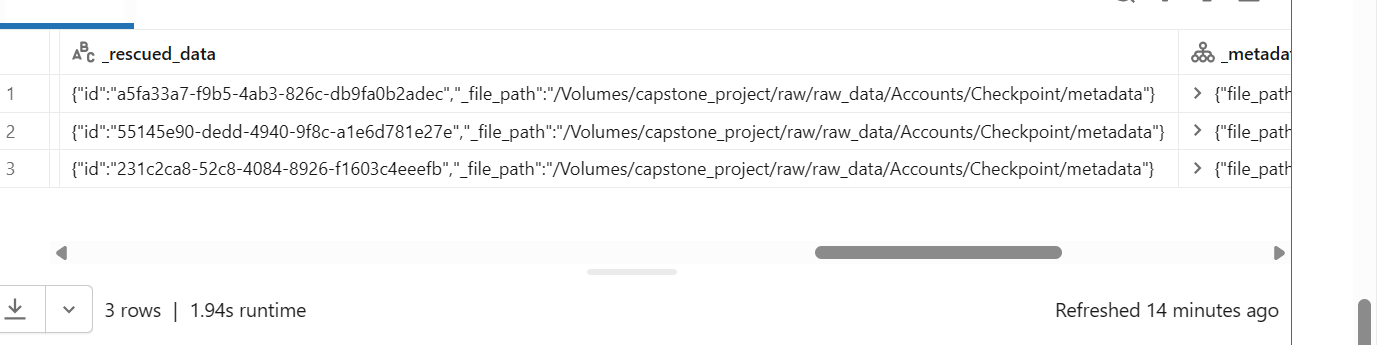
Looking at the first snapshot, it appears the path in all three records points to the checkpoint location.
The _metadata column isn’t the root cause here. The issue is that Autoloader is ingesting your checkpoint files as data.
Because Checkpoint/ lives inside the data directory, Autoloader picks up those checkpoint JSONs. They don’t match your explicit schema, so all your business columns (and _metadata after cast) become NULL, and their content goes into _rescued_data.
To fix this, consider moving the checkpoint location outside the source path.. Example given below.
df_accounts_read.writeStream.format("delta") \
.option("checkpointLocation",
"/Volumes/capstone_project/checkpoints/accounts/") \
.option("cloudFiles.schemaEvolutionMode", "addNewColumns") \
.option("mergeSchema", "true") \
.trigger(once=True) \
.toTable("capstone_project.bronze.b_accounts")
You can clean up existing bad rows from the Delta table, for example, by deleting rows where _rescued_data contains the checkpoint path.
Once the checkpoint dir is outside the data tree, those extra NULL rows will stop appearing, and your _metadata cast/schema merge will behave as expected.
Hope this helps.
If this answer resolves your question, could you mark it as “Accept as Solution”? That helps other users quickly find the correct fix.
Regards,
Ashwin | Delivery Solution Architect @ Databricks
Helping you build and scale the Data Intelligence Platform.
***Opinions are my own***







{kind=link}
{kind=link}