Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Random error related to dynamic variables in SQL -...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-13-2021 08:20 AM
Environment: Azure
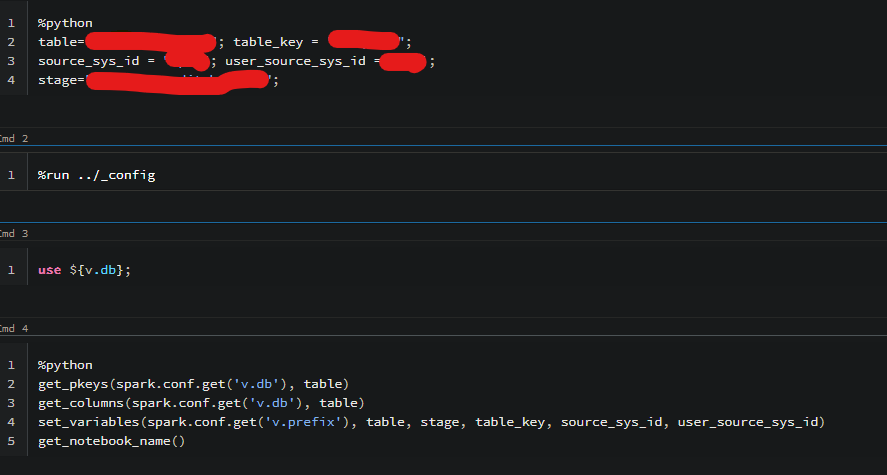
A data transformation template that take s table name as variable. The variable is set in separate notebook %run ../_config
Shallow clone is used to generate a staging table with exact same columns of target table.
A random error occurs when the ETL is running concurrent notebooks at same time.
Error log attached. (May be related to cluster resources?)
Thanks in advance if any insight is provided...
-- Create a temp table for data transformation
drop table if exists ${v.source};
create table if not exists ${v.source}
shallow clone referrals_audit;
truncate table ${v.source}; -- shallow clone also keeps data reference and we should remove it
alter table ${v.source} add columns (Error string);
Error in SQL statement: AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: at least one column must be specified for the table

Labels:
- Labels:
-
Dynamic Variables
-
Random Error
-
SQL


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-17-2022 03:28 PM
The solution is simple, don't include a shallow clone in a ETL that runs frequently. It is not necessary to change the table schema if there is no need to do so. Use a fixed table schema for a temp table in which data get truncated and reloaed.
6 REPLIES 6
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-14-2021 08:53 AM
A random error occurs when the ETL is running concurrent notebooks at same time.
Is both using the same variable value for ${v.source}?
If yes it can be just logic issue as one notebook is dropping temp table used by other notebook.
My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-14-2021 07:42 PM
@Hubert Dudek thanks for replying
The variable is different in each notebook.
The error only happened once so far, and I may need to keep eye on it.
The idea to use a notebook template with dynamics table name, all merge statements
will be dynamically generated using table column list.
Attached is _config
notebook call _config to set variables that are different because variable 'table' will be different in each notebook.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
11-28-2021 08:24 PM
The error happens again. I have removed the shallow clone in each notebook run.
My reasoning is there is an overhead of using shallow clone, and there is no need to
recreate the temp table structure each time as the table schema does not change much.
I have out shallow clone in a separate schema management task.
truncate table is the only line remains and the issue should not occur again.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2022 06:04 AM
resolved myself
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-16-2022 08:10 AM
@lizou - That's great! I'm so glad. Would you be happy to share your solution with us and then mark the answer as best? That will help others find the solution more quickly. 🙂
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-17-2022 03:28 PM
The solution is simple, don't include a shallow clone in a ETL that runs frequently. It is not necessary to change the table schema if there is no need to do so. Use a fixed table schema for a temp table in which data get truncated and reloaed.
Announcements





{kind=link}
{kind=link}
Related Content
- Dashboard Variable Display name in Warehousing & Analytics
- How to change a field when instancing cluster defined as variable? in Data Engineering
- Recommended local development workflow for dashboard CI/CD with environment-specific catalog/schema? in Warehousing & Analytics
- how to access the catalog and schema from my program in Data Engineering
- Is there a way to natively mount external Iceberg REST Catalogs (e.g., BigLake) in Unity Catalog? in Data Engineering