Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: SELECT * FROM delta doesn't work on Spark 3.2
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-14-2022 02:34 AM
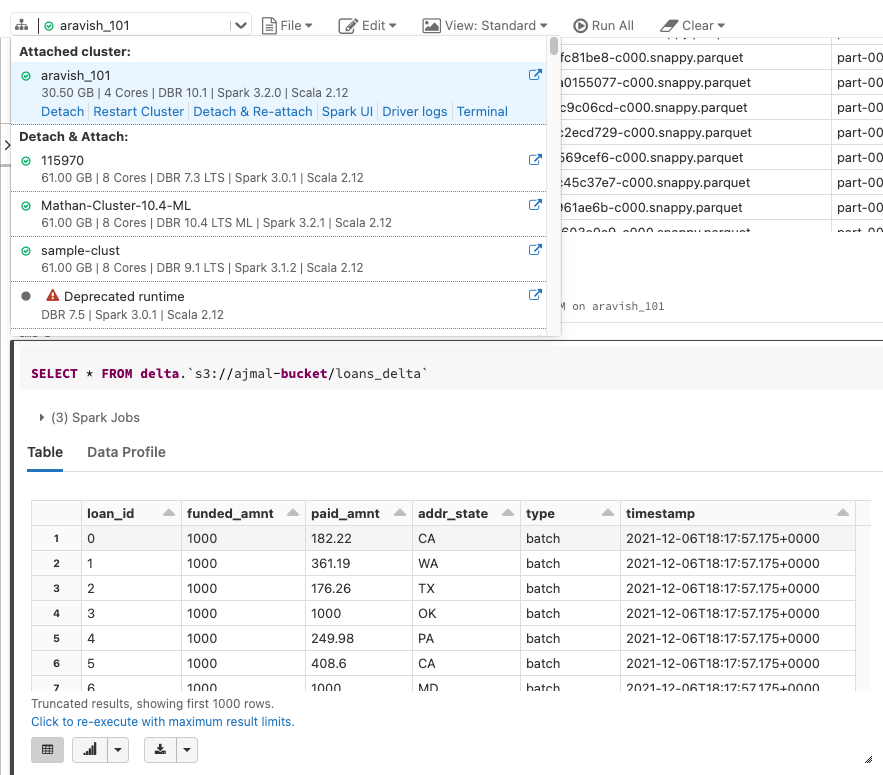
Using DBR 10 or later and I’m getting an error when running the following query
SELECT * FROM delta.`s3://some_path`
getting org.apache.spark.SparkException: Unable to fetch tables of db delta
For 3.2.0+ they recommend reading like this:
CREATE TEMPORARY VIEW parquetTable
USING org.apache.spark.sql.parquet
OPTIONS (
path "examples/src/main/resources/people.parquet"
)
SELECT * FROM parquetTable
Can you confirm this is the only way?


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-11-2022 05:46 AM
Got support from Databricks.
Unfortunately, someone created a DB called delta, so the query was done against that DB instead.
Issue was solved
4 REPLIES 4
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-14-2022 07:37 AM
@Cristobal Berger , Databricks uses dbfs, so if you want to use a path to read the data, you should use the dbfs path.
Using a view works too, btw (or define it as a table).
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-18-2022 02:02 AM
Hi @Werner Stinckens, thanks for replying.
Actually, you can read directly from S3 on PySpark and Spark SQL. Amaz on S3 documentation can show you how to do it. Now, it looks from Spark 3.2 (DBR 10 or later), it's not possible to use syntactic sugar on the FROM statement. That's what I need to confirm.
Thanks
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-04-2022 10:32 AM

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-11-2022 05:46 AM
Got support from Databricks.
Unfortunately, someone created a DB called delta, so the query was done against that DB instead.
Issue was solved
Announcements





{kind=link}
Related Content
- Extract SQL function in SQL Server federated database in Data Engineering
- Lakeflow SDP partition error in Data Engineering
- How to extract a full node from an xml string using sql in Warehousing & Analytics
- How to handle MERGE with Schema Evolution in Delta Lake in Data Engineering
- Streaming read and writing with aggregation in Data Engineering