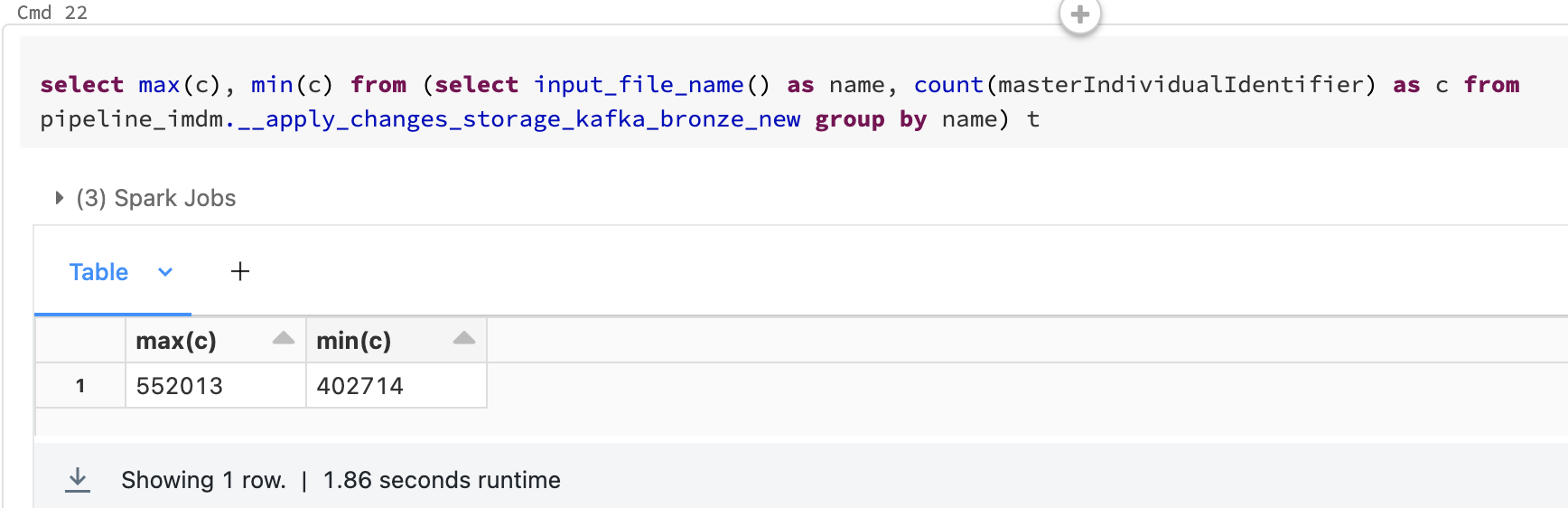
There is only 1 target table (dev approx 45Mn records), the Delta table. Backend parquet files (abfs) are dispersed by internal DBR algorithms.
Also, After ZORDER on PKey, the files got arranged in almost same size, but still slow upserts were there.
result after doing ZORDER:
 This is Dev result. Prod data size is more than 10x
This is Dev result. Prod data size is more than 10x







{kind=link}