I tried to use Spark as much as possible but experience some regression. Hopefully to get some direction how to use it correctly.
I've created a Databricks table using spark.sql
spark.sql('select * from example_view ') \
.write \
.mode('overwrite') \
.saveAsTable('example_table')
and then I need to patch some value
%sql
update example_table set create_date = '2022-02-16' where id = '123';
update example_table set create_date = '2022-02-17' where id = '124';
update example_table set create_date = '2022-02-18' where id = '125';
update example_table set create_date = '2022-02-19' where id = '126';
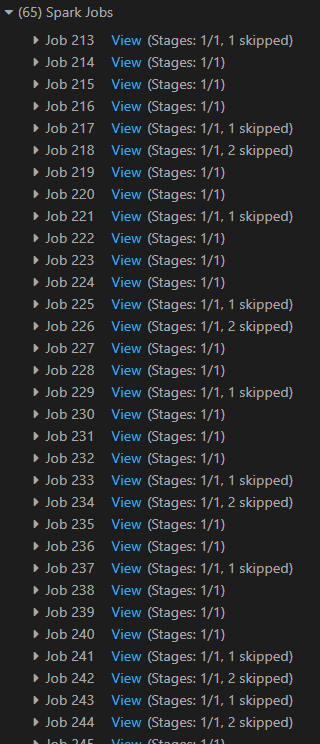
However, I found this awlfully slow since it created hundreds of spark jobs:
 Why it Spark doing this and any suggestion how to improve my code? Last thing I want to do is to convert it back to Pandas and update the cell values individually. Any suggestion is appreciated.
Why it Spark doing this and any suggestion how to improve my code? Last thing I want to do is to convert it back to Pandas and update the cell values individually. Any suggestion is appreciated.







{kind=link}