Hi experts,
I need to ingest data from an existing delta path to my own delta lake.
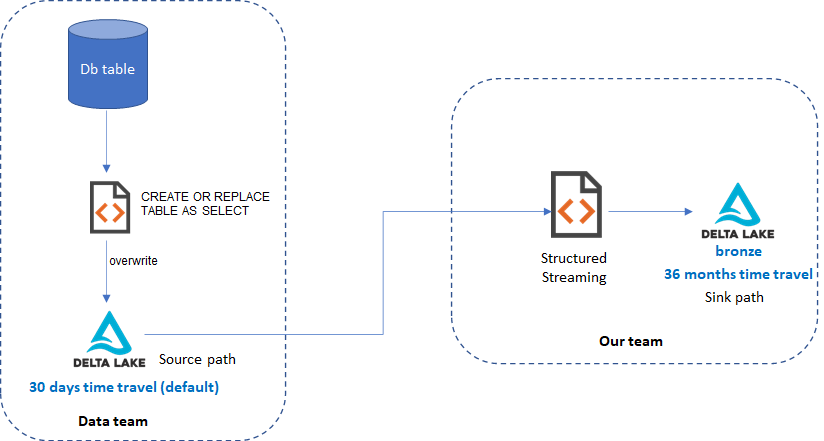
The dataflow is as shown in the diagram:
- Data team reads full snapshot of a database table and overwrite to a delta path. This is done many times per day, but not fixed schedule everyday.
I need to stream every data changes to my own delta lake for downstream consumption. Basically the same with source delta lake, but with increased log & data retention period to enable time travelling for 3 years.

I have tried the following code:
def overwrite_microbatch(microdf, batchId):
microdf.write.format("delta").mode("overwrite").save(sink_path)
(spark.readStream
.format("delta")
.option("ignoreChanges", "true")
.load(source_path)
.writeStream
.foreachBatch(overwrite_microbatch)
.option("checkpointLocation", checkpoint_path)
.start())
(.writeStream.format("delta").outputMode("append") does not work because "append" mode causes duplication and writeStream does NOT support "overwrite" mode.)
Which works, but I ran into 2 problems:
- Sink path is not storage optimized, i.e each version stores a full table snapshot in a .snappy.parquet file instead of only incremental changes.
- If my streaming job fails to consume one or more versions, then the next microbatch contains a concat of 2+ versions that are not yet consumed. Which again causes duplication in sink path.
What should be the right approach for this scenario?
Any idea is very much appreciated. Thanks!
Best Regards,
Vu







{kind=link}