Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- Re: Suggestion Needed for a Orchestrator/Scheduler...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Suggestion Needed for a Orchestrator/Scheduler to schedule and execute Jobs in an automated way
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-10-2022 04:34 AM
Hello Friends,
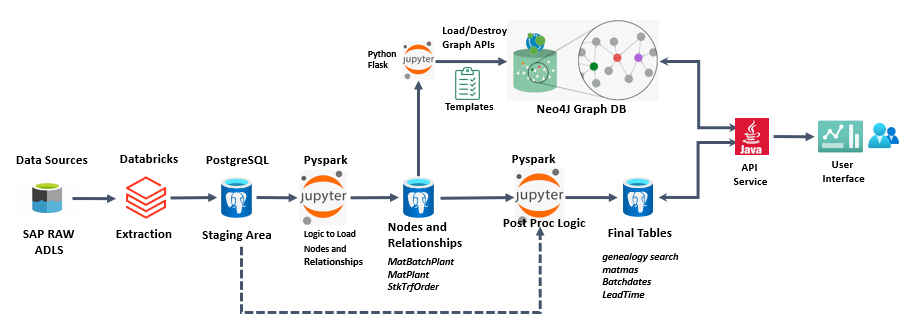
We have an application which extracts dat from various tables in Azure Databricks and we extract it to postgres tables (postgres installed on top of Azure VMs). After extraction we apply transformation on those datasets in postgres tables with the help of spark programs written on Jupiter notebook and load the data to Neo4j graph database (Neo4j installed on Another Azure VM). For now we are doing the extraction through SQL queries and for transformation on Postgres we are leveraging Python(Spark) Programs. As the there are lot of tables (More than 100) and there is dependency , It is not possible to run everything manually. Hence we are looking for a Orchestrator and Scheduler where we can create our job execution workflow and schedule them to run at a particular time frame. Can you please suggest one ? Appreciate in advance. I am attaching the Architecture of the application here in this post.



14 REPLIES 14
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-10-2022 04:37 PM
Apache Airflow seems to be the standard kind of tool for this.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-12-2022 11:46 PM
Thanks for your reply @Joseph Kambourakis , will explore more on Apache Airflow and try it out
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-11-2022 12:58 AM
You should also be able to use Azure Data Factory for orchestration and Scheduling pipelines.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-12-2022 11:48 PM
Thanks for your response @Arvind Ravish
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-11-2022 03:04 AM
@Badal Panda please consider Databricks Workflows. It's fully-managed, reliable and supports your scenario.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-12-2022 11:48 PM
thanks for your response @Bilal Aslam
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-17-2022 05:02 AM
Hi @Kaniz Fatma ,
We are trying with Azure Data factory first by migrating our jupyter code to Databricks Notebooks. However the pipeline failed with below error while writing to a particular table in postgres from databricks -
org.apache.spark.SparkException: Job 910 cancelled because Task 30248 in Stage 1422 exceeded the maximum allowed ratio of input to output records (1 to 24919, max allowed 1 to 10000); this limit can be modified with configuration parameter spark.databricks.queryWatchdog.outputRatioThreshold
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
06-18-2022 12:42 AM
Do you have a giant cross join that you are unaware of? or some join condition that is producing many rows in the output...
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
07-29-2022 11:44 AM
Hi @Badal Panda,
Just a friendly follow-up. Do you still looking for help?
This error is coming from high concurrency cluster:
org.apache.spark.SparkException: Job 910 cancelled because Task 30248 in Stage 1422 exceeded the maximum allowed ratio of input to output records (1 to 24919, max allowed 1 to 10000); this limit can be modified with configuration parameter spark.databricks.queryWatchdog.outputRatioThreshold
solution: https://docs.microsoft.com/en-us/azure/databricks/spark/latest/spark-sql/query-watchdog
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-01-2022 06:34 AM
Hello @Jose Gonzalez ,
Thanks for your response , the issue is resolved.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-18-2022 07:57 AM
Hey there @Badal Panda
Hope you are doing well.
We are glad to hear that you were able to resolve your issue. Would be happy to mark an answer as best so that other members can find the solution more quickly?
Thanks!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-18-2022 09:53 PM
Hi @Vartika Nain ,
Sure I can share details regarding the Orchestrator/Scheduler , but recently there have been changes to our design architecture with source systems so let me explain briefly
- For our application ,we initially extracted data from ADLS using databricks notebooks (Spark SQL / Pyspark) and ingested data to postgres and from postgres to Neo4j load we used Jupyter as highlighted in my architecture diagram that I shared here. Based on the suggestion I got here from experts we tried with Apache Airflow but did not get success , with Databricks Jobs we could only schedule notebooks in databricks but not the jobs that were running on Jupyter , We also tried ADF but ADF has no connectors to connect with Jupyter. So we resolved the issue with a Hybrid approach of Databricks Workflows (for all databricks notebooks) + CRONTAB for Jupyter Notebooks. The Jupyter is hosted on a local Linux machine so we used cron jobs with the help of a shell script for all notebooks of Jupyter.
- Now our source system is changing and we need to extract from synapse. So we are going to use Azure Data factory as our orchestrator and scheduler for all workloads.
I hope I have answered your question. Please let me know if there is anything else I can clarify.
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
08-22-2022 10:01 AM
Hey @Badal Panda
Thank you so much for getting back to us. It's really great of you to send in your answer.
We really appreciate your time.
Wish you a great Databricks journey ahead!
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-05-2022 09:29 PM
You can leverage Airflow, which provides a connector for databricks jobs API, or can use databricks workflow to orchestrate your jobs where you can define several tasks and set dependencies accordingly.
Announcements





{kind=link}
Related Content
- Stop Translating Alteryx Boxes - A Lakebridge-assisted, test-driven migration to Azure Databricks in Data Engineering
- E2E MLOps Part 1: How to build and govern models with AutoML, MLflow, and Unity Catalog in Machine Learning
- ALTER Not Working in Databricks for external Table. in Data Engineering
- How to Prepare Enterprise Data for AI Agents: A Practical Guide in Data Engineering
- Automation for any script changes in databricks and bit bucket in Data Engineering