10-22-2023 10:22 PM
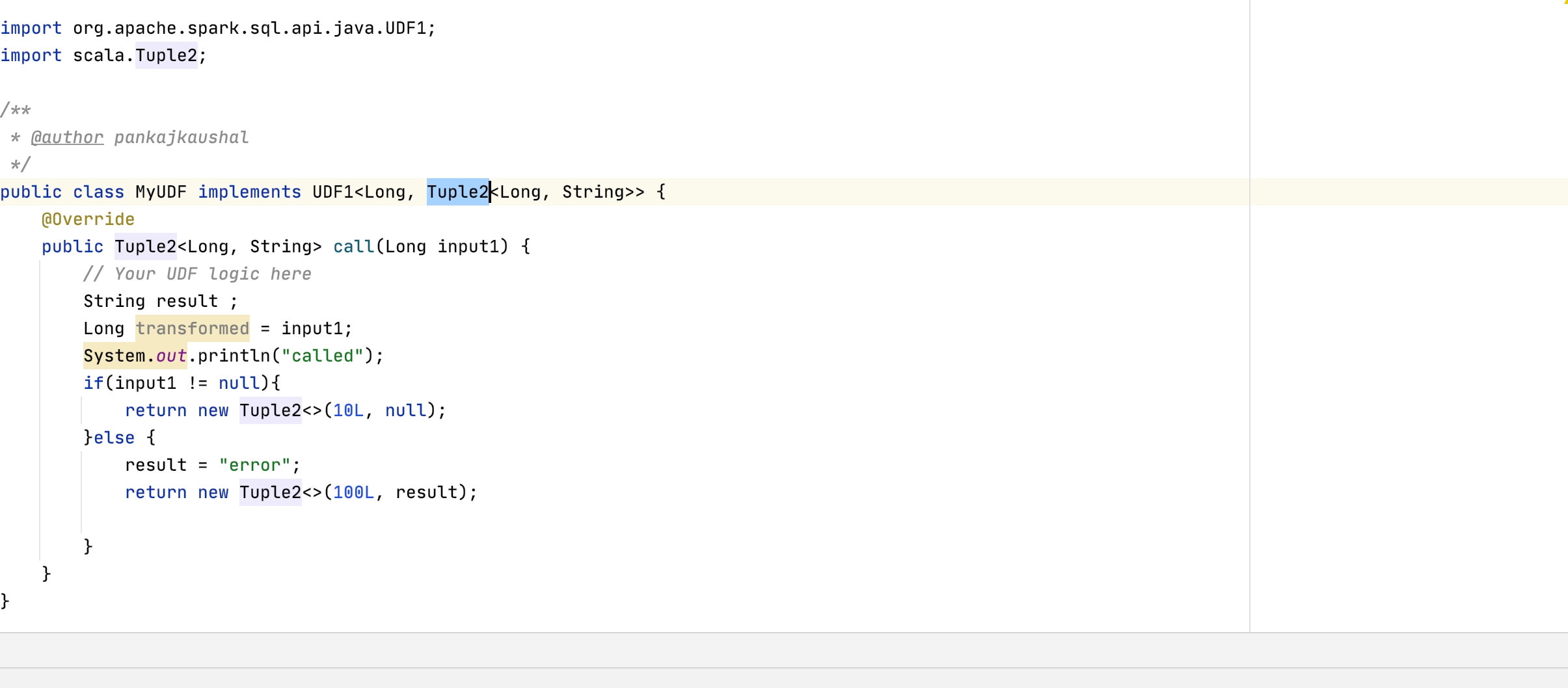
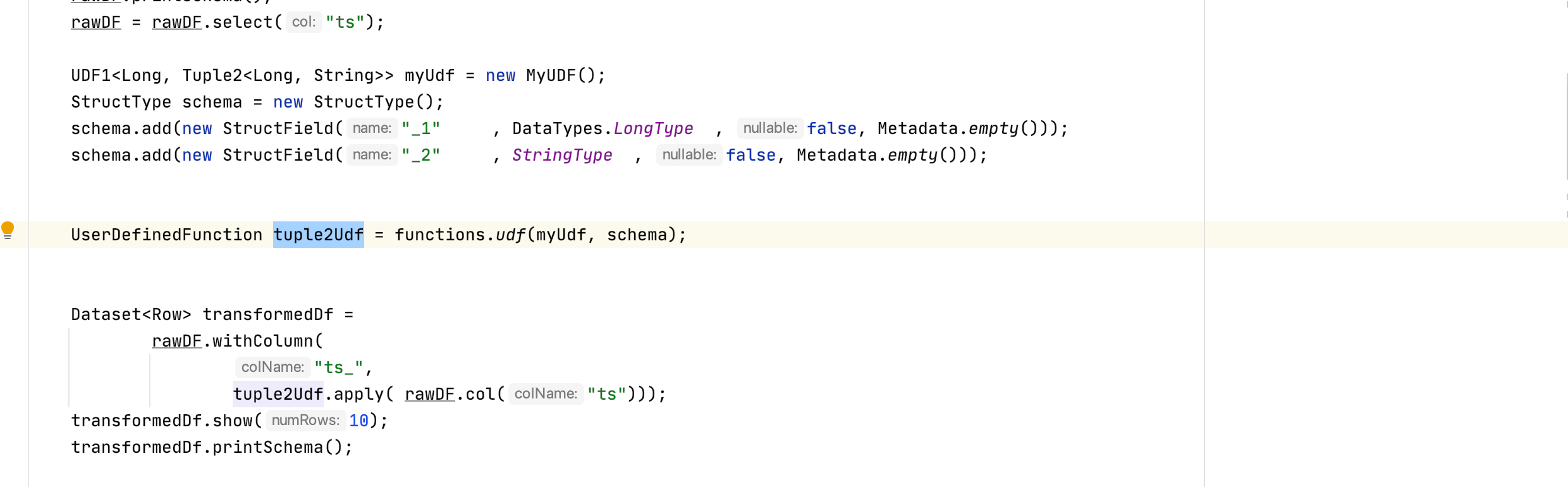
From a UDF i am trying to return a tuple. But looks like the tuple is not serialising and hence getting empty tuple.
Can some help me on this.
Attached code and output.
never-displayed







{kind=link}
{kind=link}
{kind=link}