I have a dataframe that is a series of transformation of big data (167 million rows) and I want to write it to delta files and tables using the below :
try:
(df_new.write.format('delta')
.option("delta.minReaderVersion", "2")
.option("delta.minWriterVersion", "5")
.option("spark.databricks.delta.optimizeWrite.enabled",True)
.option("delta.columnMapping.mode", "name")
.mode('overwrite')
.option("overwriteSchema", True)
.save(f'/mnt/mymountpoint/Gold_tables/tasoapplans'))
try:
df_new.write.insertInto('Gold_tables.tasoapplans', overwrite=True)
except:
spark.sql("create table IF NOT EXISTS Gold_tables.tasoapplans using delta location '/mnt/mymountpoint/Gold_tables/tasoapplans'")
except Exception as e:
dbutils.notebook.exit(str(e))
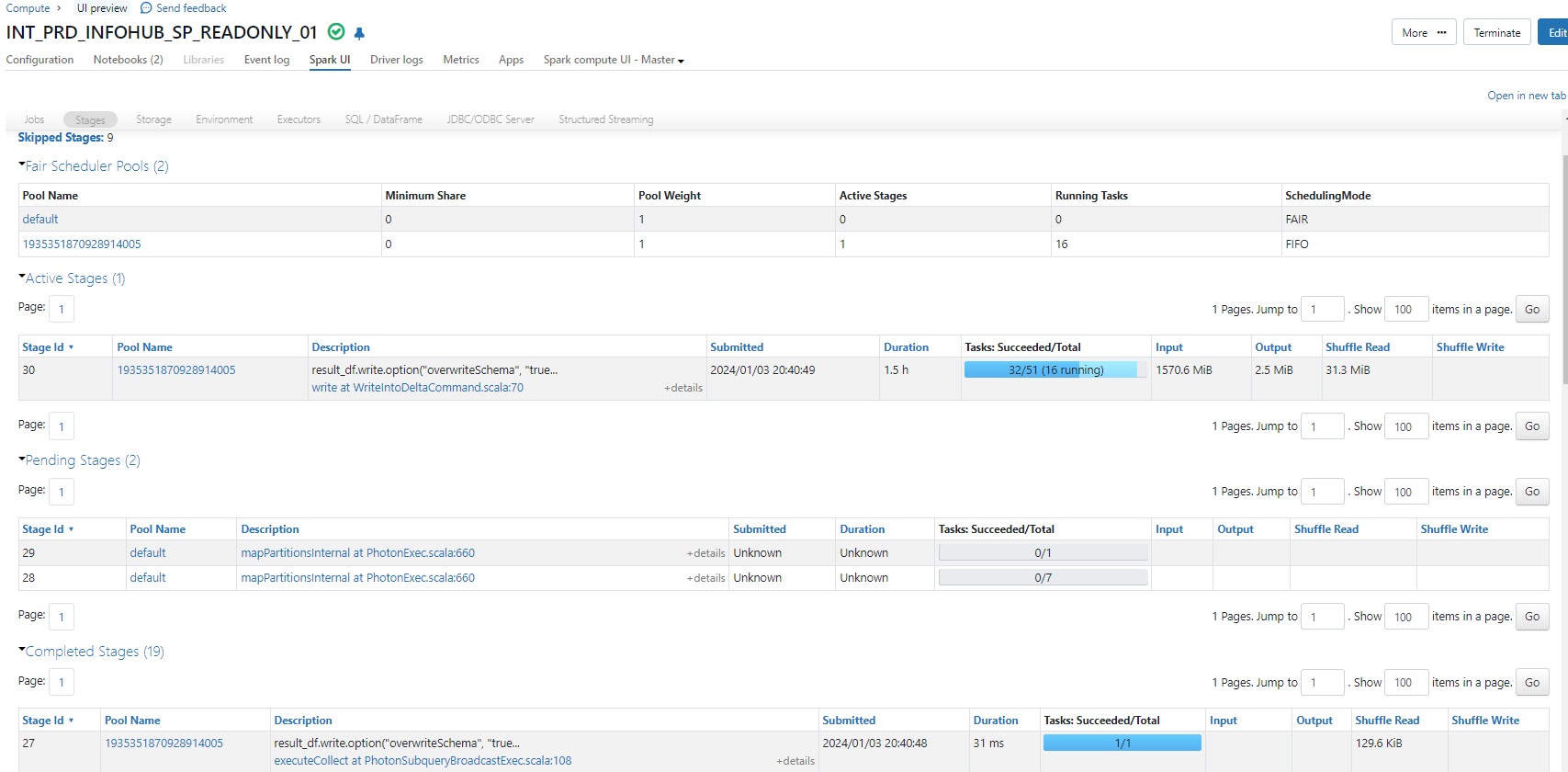
But the writing is taking too much time(query = 1 hour, writing 1 hour 30 minutes)
Cluster used is :
Memory optimized cluster Standard_DS12_v2 (28GB memroy,4 Cores)
Use photon Acceleration
min workers:2
max workers:8
How can I improve the writing?







{kind=link}