Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Engineering
Join discussions on data engineering best practices, architectures, and optimization strategies within the Databricks Community. Exchange insights and solutions with fellow data engineers.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Engineering
- XML Auto Loader rescuedDataColumn Doesn't Rescue A...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
XML Auto Loader rescuedDataColumn Doesn't Rescue Array Fields
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2025 03:54 AM
Hiya! I'm interested whether anyone has a solution to the following problem. If you load XML using Auto Loader or otherwise and set the schema to be such that a single value is assumed for a given xpath but the actual XML contains multiple values (i.e. should be an array) then the additional values aren't rescued so become irrecoverably dropped.
Example XML data: <Message><Attribute>1</Attribute><Attribute>2</Attribute></Message>
rowTag: Message
Schema applied: Attribute INTEGER (actual schema should be Attribute ARRAY<INTEGER>)
Result: Table containing one column Attribute with 2 as the value and the rescuedDataColumn is empty.
In the above example the value 1 in the additional Attribute tag is dropped and cannot be recovered because it doesn't land in the rescuedDataColumn. I need a way to ensure this data is not dropped because we cannot know whether any given tag in the XML being read has one node corresponding to it or is actually an array.


17 REPLIES 17
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2025 10:09 AM - edited 01-24-2025 10:10 AM
Hi @peter_ticker ,
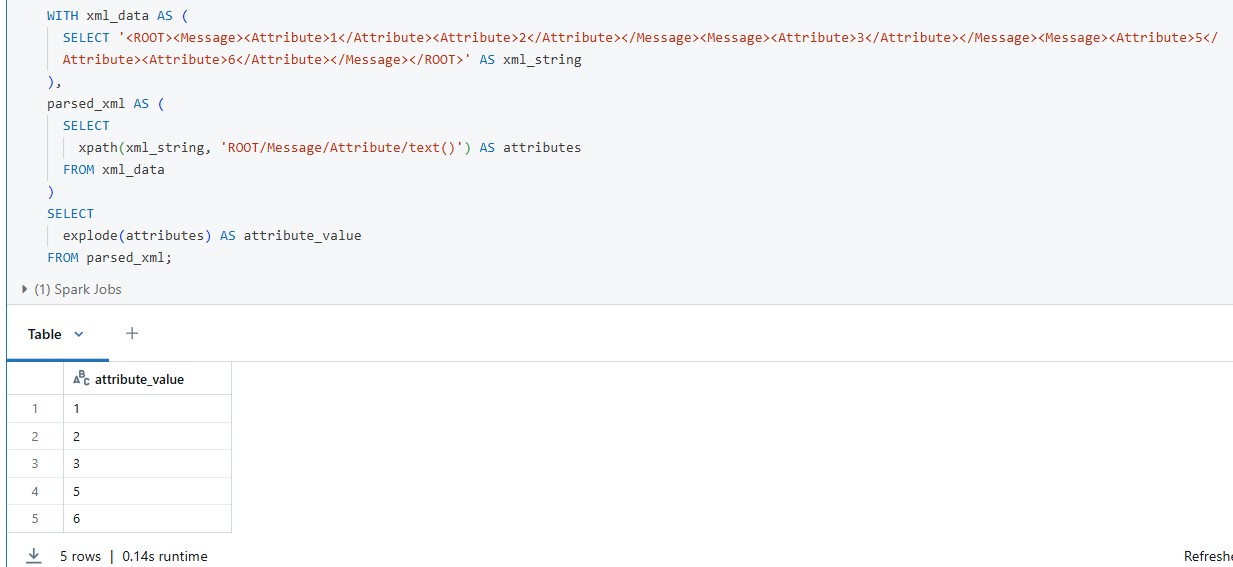
Can you try this SQL snippet (refer to the attachment).
WITH xml_data AS (
SELECT '<ROOT><Message><Attribute>1</Attribute><Attribute>2</Attribute></Message><Message><Attribute>3</Attribute></Message><Message><Attribute>5</Attribute><Attribute>6</Attribute></Message></ROOT>' AS xml_string
),
parsed_xml AS (
SELECT
xpath(xml_string, 'ROOT/Message/Attribute/text()') AS attributes
FROM xml_data
)
SELECT
explode(attributes) AS attribute_value
FROM parsed_xml;
However, this approach may not work for complex and nested schemas.
When you are dealing with large and complex schema, I personally recommend either to convert to json or make use of external libraries like Maven spark-xml (com.databricks:spark-xml_2.12:0.16.0) with predefined schema.
Parsing using Maven Library:
- Predefine the schema
- Read the datafile as a dataframe with predefined schema - just schema is captured
- Flatten it node level
- Finally select the attributes that you wanted from the file.
I tried different approaches and settled with this as a best fit for my use case. This works even for very complex nested structure as well.
Let me know for anything, else please mark as accepted solution.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 12:45 AM
Yes I understand that XPATH allows all the nodes to be selected but you're assuming that I already know there will be multiple Attribute nodes. My use case is streaming with a rather complicated schema so I'm concerned about the above example in that Databricks doesn't rescue data when the schema is initially misconfigured.
Converting to JSON would have the same problem - if there aren't files with multiple nodes then the converted JSON wouldn't use an array to store the resulting field which would lead to issues when multiple nodes start appearing.
Does the Maven library rescue data that wasn't captured in the schema like in the above example?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-24-2025 09:47 PM
Hi,
If reading XML in databricks is concern to you, you can refer to below link on how to parse XML files in databricks.
If you find this helpful, mark it as solution.
Regards,
Avinash N

Working with XML files and convert it into a structured DataFrame for downstream use can be a common requirement when dealing with structured data formats, especially in legacy systems. Scenario Imagine you're working with an insurance dataset, stored in XML format, that contains details such as aud
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 12:49 AM
Your reference provides nothing which would help with my question. Using BeautifulSoup you have to know exactly what the schema of the XML is in order to pull it into a Python object. If you incorrectly interpret the XML, then the result will be the same as my example.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 12:50 AM
Since DBR 14.3 XML supports is included natively, so there's no real reason to recommend third-party libraries anymore.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 12:52 AM
Hiya! Yep I'm intending to use Databricks native XML reader but my question raises an issue with the rescuedDataColumn that personally prevents me from being able to use it.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 12:56 AM
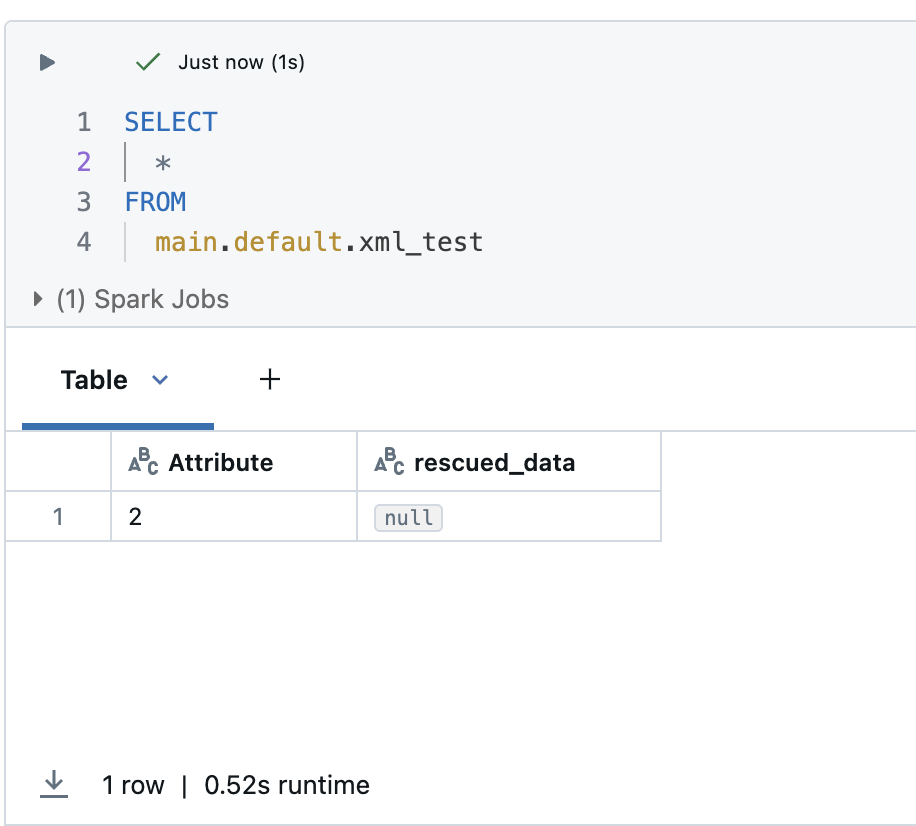
@peter_tickerIn your screenshot, I don't see you using Auto Loader. This might be the reason, why rescued data is empty for you.
Besides, you can also play around with mode and columnNameOfCorruptRecord
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 12:59 AM
I used FROM_XML as it's the easiest to provide a reproducible example. The behaviour is the same in auto loader or otherwise. Databricks accepts that the schema I provided in the example is valid so doesn't consider the record corrupt or produce any rescued data. This is my concern.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 04:10 AM
Have you already checked columnNameOfCorruptRecord? I've seen cases in which this column contained data instead of the rescued data column. I believe the reason for that the XML parser fails before Auto Loader kicks in
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 04:18 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 04:32 AM
This column will not appear magically, if you don't add it to your target table 😉
As an alternative, instead of looking at this table, you can also look directly at the source, e.g. replacing toTable with display
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 04:36 AM
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 05:29 AM
Ah, now I see what you did.
`rowTag` is not the root element, it's the element which describes your rows within the root element. In your case, Message is the root element, Attribute are the rows. Meaning, set rowTag to Attribute. And since Attribute itself doesn't contain any sub-elements, you also need to set valueTag to Attribute
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-27-2025 05:34 AM
No - I intended Message to be the element which describes rows. The example I set is one row of data containing a simple array field called Attribute.
Announcements





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Related Content
- Getting error while using Live.target_table in dlt pipeline in Data Engineering
- Old files also getting added in dlt autoloader in Data Engineering
- autoloader break on migration from community to trial premium with s3 mount in Data Engineering
- Auto Loader: Empty fields (discovery_time, commit_time, archive_time) in cloud_files_state in Data Engineering