Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Data Governance
Join discussions on data governance practices, compliance, and security within the Databricks Community. Exchange strategies and insights to ensure data integrity and regulatory compliance.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Data Governance
- Re: GC (Metadata GC Threshold) issue
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-14-2022 12:16 AM
Hi All,
I am facing the GC metadata issue while performing distributed computing on Spark.
2022-01-13T22:02:28.467+0000: [GC (Metadata GC Threshold) [PSYoungGen: 458969K->18934K(594944K)] 458969K->18958K(1954816K), 0.0144028 secs] [Times: user=0.05 sys=0.01, real=0.02 secs]
2022-01-13T22:02:28.482+0000: [Full GC (Metadata GC Threshold) [PSYoungGen: 18934K->0K(594944K)] [ParOldGen: 24K->17853K(823296K)] 18958K->17853K(1418240K), [Metaspace: 20891K->20891K(1067008K)], 0.0201195 secs] [Times: user=0.14 sys=0.01, real=0.02 secs]
2022-01-13T22:02:29.459+0000: [GC (Metadata GC Threshold) [PSYoungGen: 432690K->84984K(594944K)] 450544K->105009K(1418240K), 0.0226140 secs] [Times: user=0.17 sys=0.05, real=0.03 secs]
2022-01-13T22:02:29.481+0000: [Full GC (Metadata GC Threshold) [PSYoungGen: 84984K->0K(594944K)] [ParOldGen: 20025K->91630K(1360384K)] 105009K->91630K(1955328K), [Metaspace: 34943K->34943K(1079296K)], 0.0307833 secs] [Times: user=0.13 sys=0.07, real=0.03 secs]
Cluster config :
Nodes - r5.4xlarge (128 GB, 16 cores)
8 Worker nodes
Spark Config :
spark_home_set("/databricks/spark")
config <- spark_config()
config$spark.sql.shuffle.partitions = 480
config$spark.executor.cores = 5
config$spark.executor.memory = "30G"
config$spark.rpc.message.maxSize = 1945
config$spark.executor.instances = 24
config$spark.driver.memory = "30G"
config$spark.sql.execution.arrow.sparkr.enabled = TRUE
config$spark.driver.maxResultSize = 0
options(sparklyr.sanitize.column.names.verbose = TRUE)
options(sparklyr.verbose = TRUE)
options(sparklyr.na.omit.verbose = TRUE)
options(sparklyr.na.action.verbose = TRUE)
options(java.parameters = "-Xmx8000m")
sc <- spark_connect(method = "databricks", master = "yarn-client", config = config, spark_home = "/databricks/spark")
Please let me know how to fix this issue. Tried different approaches but I am getting same error all the time.
Thanks,
Chandan
Labels:
- Labels:
-
Spark config


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-30-2022 11:20 AM
Hi @Jose Gonzalez ,
Yes, the issue got resolved with the following spark config.
conf = spark_config()
conf$sparklyr.apply.packages <- FALSE
sc <- spark_connect(method = "databricks", config = conf)
9 REPLIES 9
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-14-2022 12:18 AM
Hi @Kaniz Fatma ,
If you have any idea regarding this, please let me know.
Thanks,
Chandan
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-14-2022 05:18 AM
Can you try to run a test with maximum simplified spark_connect (so just method and spark_home).
Additionally please check following:
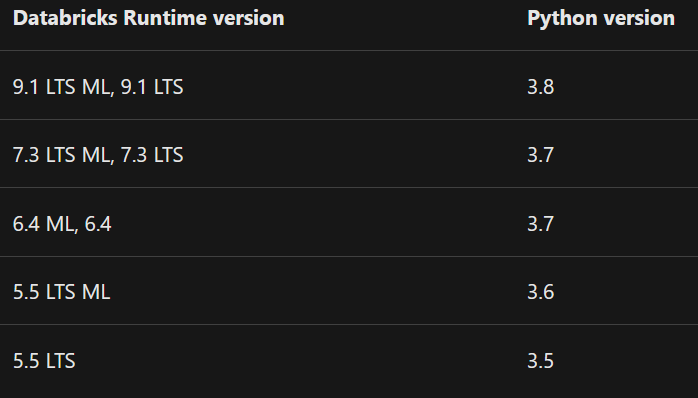
- Only the following Databricks Runtime versions are supported:
- Databricks Runtime 9.1 LTS ML, Databricks Runtime 9.1 LTS
- Databricks Runtime 7.3 LTS ML, Databricks Runtime 7.3 LTS
- Databricks Runtime 6.4 ML, Databricks Runtime 6.4
- Databricks Runtime 5.5 LTS ML, Databricks Runtime 5.5 LTS
- The minor version of your client Python installation must be the same as the minor Python version of your Azure Databricks cluster. The table shows the Python version installed with each Databricks Runtime.

My blog: https://databrickster.medium.com/
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-14-2022 07:59 AM
Hi @Hubert Dudek ,
Thanks for the reply, I am running R code. I tried the approach you have mentioned got the same issue.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-23-2022 05:04 PM
Hi @Chandan Angadi ,
Are you getting any other error or warning message? for example in your log4j or the std error logs?
I would also recommend to run your code with the default values. Without these settings:
config <- spark_config()
config$spark.sql.shuffle.partitions = 480
config$spark.executor.cores = 5
config$spark.executor.memory = "30G"
config$spark.rpc.message.maxSize = 1945
config$spark.executor.instances = 24
config$spark.driver.memory = "30G"
config$spark.sql.execution.arrow.sparkr.enabled = TRUE
config$spark.driver.maxResultSize = 0
Just to narrow down and identify the the message happens with all the default values or not. Some of these Spark configs are not needed in Databricks, unless you want to fine tune your job. In this case we need to make sure your job runs fine, to have a reference point.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-05-2022 04:53 PM
hi @Chandan Angadi ,
Just a friendly follow-up. Are you still affected by this error message? please let us know if we can help.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-30-2022 11:20 AM
Hi @Jose Gonzalez ,
Yes, the issue got resolved with the following spark config.
conf = spark_config()
conf$sparklyr.apply.packages <- FALSE
sc <- spark_connect(method = "databricks", config = conf)
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-28-2022 09:46 AM
Hey @Chandan Angadi
Hope you are doing great!
Just checking in. Were you able to resolve your issue? If yes, would you like to mark an answer as best? It would be really helpful for the other members.
We'd love to hear from you.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-30-2022 11:18 AM
Hi @Vartika Nain ,
Sorry for the late reply and sorry for others as well had some health issues so couldn't reply early.
Yes, the issue got resolved with the following spark config.
conf = spark_config()
conf$sparklyr.apply.packages <- FALSE
sc <- spark_connect(method = "databricks", config = conf)
Anonymous
Not applicable
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-02-2022 06:05 AM
Hi @Chandan Angadi
Hope you are doing well now.
Thanks for getting back to us and sending in your solution. Would you like to mark an answer as best?
Thanks!
Announcements





{kind=link}
Related Content
- Materialized View backing pipeline retains old Unity Catalog after catalog rename in Data Engineering
- Bug? Genie Space benchmark evaluates "Score reason" wrongly as "Empty result" on agent mode in Data Engineering
- Managing IPYNB cell timestamps in source control in Data Engineering
- Auto Loader with ignoreMissingFiles and useManagedFileEvents fails on Classic Compute in Data Engineering
- How to get MLflow OpenAI autolog traces from PySpark mapInPandas workers (and some pitfalls) in Generative AI