When I first got into managing schemas in Databricks, it took me a while to realize that putting in a little planning up front could save me a ton of headaches later on.
I was working with these deeply nested, constantly changing JSON files. At first, I leaned on automatic schema inference—seemed like the easiest way to get things going. But over time, I started noticing problems: missing fields, inconsistent structures, and Spark just not interpreting the data the way I expected.
That’s when I came across schemaHints, and it turned out to be a game changer. It’s a great way to handle semi-structured and nested JSON data in Databricks, especially when using Autoloader or the read_files function.
Instead of leaving Spark to figure it all out, I started giving it just enough guidance with schemaHints.
Here's a quick example that helped me get more consistent results:
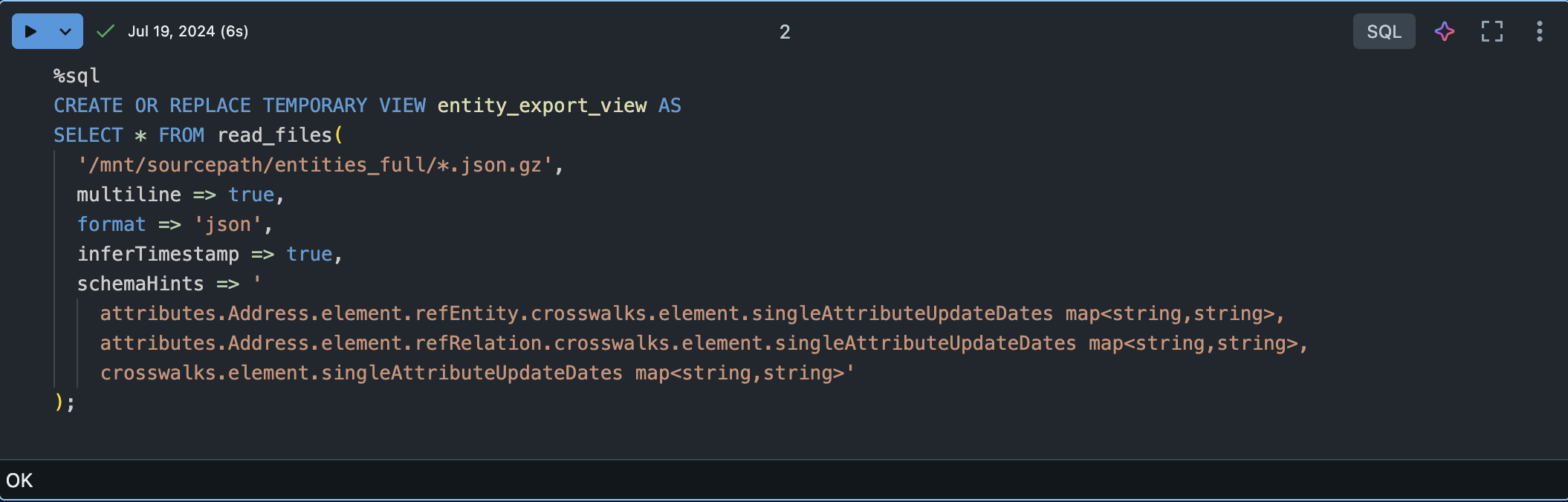
%sql
CREATE OR REPLACE TEMPORARY VIEW entity_export_view AS
SELECT * FROM read_files(
'/mnt/sourcepath/entities/*.json.gz',
multiline => true,
format => 'json',
inferTimestamp => true,
schemaHints => '
attributes.Address.element.refEntity.crosswalks.element.singleAttributeUpdateDates map<string,string>,
attributes.Address.element.refRelation.crosswalks.element.singleAttributeUpdateDates map<string,string>,
crosswalks.element.singleAttributeUpdateDates map<string,string>'
);
tip: schemaHints helps Spark understand just enough about your data structure so it can process it without blowing up, while still being flexible enough to adapt to changes.
If you're dealing with messy or shifting JSON data, this is definitely a trick worth keeping
https://docs.databricks.com/aws/en/ingestion/cloud-object-storage/auto-loader/schema
#databricks #schemamanagemnt #DataEngineering #BigData #schemaHints







{kind=link}