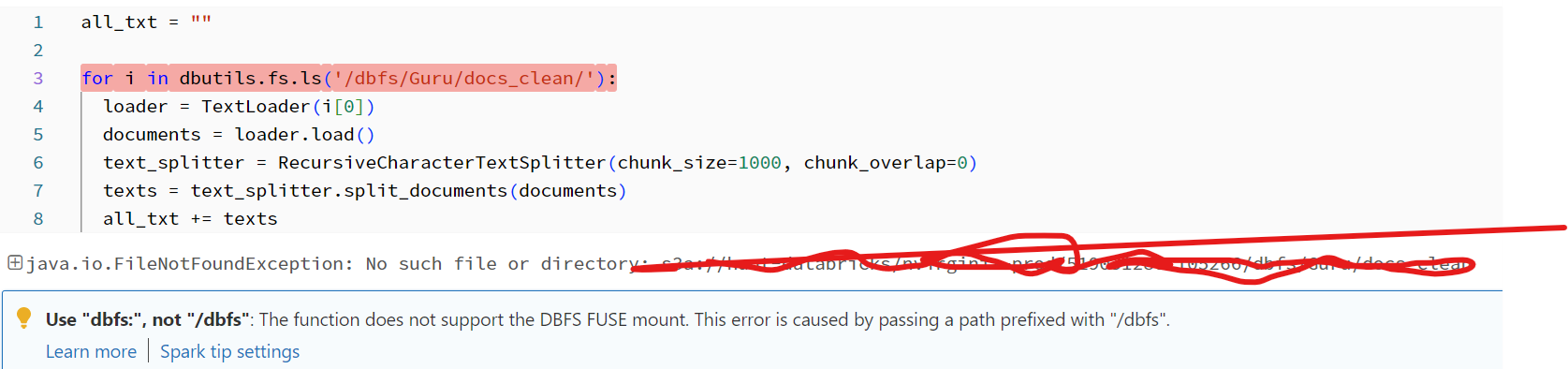
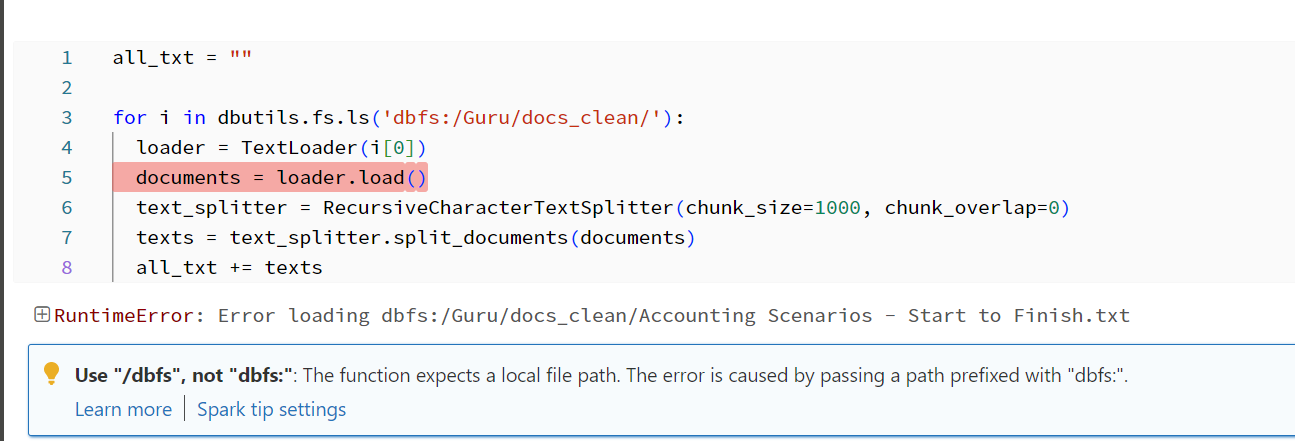
I ended up tinkering around and found I needed to use the os package to access it as a '/dbfs/' filepath:
#Iterate through directory of docs, load, split then add to total list
txt_ls = []
for i in os.listdir(dir_ls):
filename = os.path.join(dir_ls, i)
loader = TextLoader(filename)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
txt_ls.append(texts)









{kind=link}
{kind=link}