Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Machine Learning
Dive into the world of machine learning on the Databricks platform. Explore discussions on algorithms, model training, deployment, and more. Connect with ML enthusiasts and experts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Machine Learning
- Re: Problem when serving a langchain model on Data...
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Problem when serving a langchain model on Databricks
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
02-06-2024 11:06 AM
I´m trying to model serving a LLM LangChain Model and every time it fails with this messsage:
[6b6448zjll] [2024-02-06 14:09:55 +0000] [1146] [INFO] Booting worker with pid: 1146
[6b6448zjll] An error occurred while loading the model. You haven't configured the CLI yet! Please configure by entering `/opt/conda/envs/mlflow-env/bin/gunicorn configure`.
I´m trying to enable using
"scale_to_zero_enabled": "False",
"workload_type": "GPU_SMALL",
"workload_size": "Small",
I tried using code, using UI and it shows this error every time.
I´m logging the model with success as follows
I tried using code, using UI and it shows this error every time.
I´m logging the model with success as follows
import mlflow
import langchain
from mlflow.models import infer_signature
with mlflow.start_run() as run:
signature = infer_signature(question, answer)
logged_model = mlflow.langchain.log_model(
lc_model=llm_chain,
artifact_path="model",
registered_model_name="llamav2-llm-chain",
metadata={"task": "llm/v1/completions"},
pip_requirements=["mlflow==" + mlflow.__version__,"langchain==" + langchain.__version__],
signature=signature,
await_registration_for=900 # wait for 15 minutes for model registration to complete
)
# Load the retrievalQA chain
loaded_model = mlflow.pyfunc.load_model(logged_model.model_uri)


25 REPLIES 25
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-09-2024 09:08 AM - edited 03-09-2024 09:09 AM
All, I've fixed the error. Though, to be honest, I'm not exactly sure what ended up doing it. I was trying to do it systematically, but I lost track. None the less, I hope my below code helps.
def get_retriever(persist_dir: str = None):
import gunicorn
from databricks.vector_search.client import VectorSearchClient
from langchain_community.vectorstores import DatabricksVectorSearch
from langchain_community.embeddings import DatabricksEmbeddings
from langchain_community.chat_models import ChatDatabricks
from langchain.chains import RetrievalQA
import logging
import traceback
logging.basicConfig(filename='error.log', level=logging.DEBUG)
print('libraries loaded')
# token = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
embedding_model = DatabricksEmbeddings(endpoint="databricks-bge-large-en")
print('initialized embedding_model')
#Get the vector search index
vsc = VectorSearchClient(workspace_url=os.environ["DATABRICKS_HOST"],
personal_access_token=os.environ["DATABRICKS_TOKEN"],
disable_notice=True
)
print('initialized VectorSearchClient')
vs_index = vsc.get_index(
endpoint_name='vectorsearch',
index_name=vsIndexName
)
print('initialized vs_index')
# Create the retriever
try:
print('trying to initialize vectorstore')
vectorstore = DatabricksVectorSearch(
vs_index, text_column="content", embedding=embedding_model, columns=["url"]
)
retriever = vectorstore.as_retriever(search_kwargs={'k': 4})
print('initialized vectorstore')
return retriever
except BaseException as e:
print("An error occurred:", str(e))
traceback.print_exc()
from langchain.vectorstores import DatabricksVectorSearch
import os
from langchain_community.chat_models import ChatDatabricks
from langchain.chains import RetrievalQA
from langchain import hub
prompt = hub.pull("rlm/rag-prompt", api_url="https://api.hub.langchain.com")
retriever = get_retriever()
chat_model = ChatDatabricks(endpoint="databricks-llama-2-70b-chat")
qa_chain = RetrievalQA.from_chain_type(
chat_model,
retriever=retriever,
chain_type_kwargs={"prompt": prompt}
)
import langchain
from mlflow.models import infer_signature
with mlflow.start_run(run_name=runName) as run:
question = "qiestopm jere?"
result = qa_chain({"query": question})
signature = infer_signature(result['query'], result['result'])
model_info = mlflow.langchain.log_model(
qa_chain,
loader_fn=get_retriever, # Load the retriever with DATABRICKS_TOKEN env as secret (for authentication).
artifact_path="chain",
registered_model_name=fq_model_name,
pip_requirements=[
"mlflow",
"langchain",
"langchain_community",
"databricks-vectorsearch",
"pydantic==2.5.2 --no-binary pydantic",
"cloudpickle",
"langchainhub"
],
input_example=result,
signature=signature,
)
import urllib
import json
import mlflow
import requests
import time
from mlflow.tracking import MlflowClient
client = MlflowClient()
model_name = f"{fq_model_name}"
serving_endpoint_name = servingName
#TODO: use the sdk once model serving is available.
serving_client = EndpointApiClient()
auto_capture_config = {
"catalog_name": catalog,
"schema_name": db,
"table_name_prefix": serving_endpoint_name
}
environment_vars={
"DATABRICKS_HOST" : "{{secrets/azurekeyvault/hostsecrethere}}",
"DATABRICKS_TOKEN" : "{{secrets/azurekeyvault/pathere}}"
}
serving_client.create_endpoint_if_not_exists(serving_endpoint_name,
model_name=model_name.lower(),
model_version = 33,
workload_size="Small",
scale_to_zero_enabled=True,
wait_start = True,
auto_capture_config=auto_capture_config,
environment_vars=environment_vars
)
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-14-2024 04:48 AM
Thank you @DataWrangler
Mine is now successfully deployed, I am now facing this 'Forbidden for url' issue whenever I query the endpoint.
In our workspace, PAT are not allowed hence we need to use a service principal.
Probable cause is the service principal?
03 Client Error: Forbidden for url: /serving-endpoints/databricks-mixtral-8x7b-instruct/invocations
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-14-2024 01:23 PM
@SwaggerP @DataWrangler Any solution?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-14-2024 06:12 PM
Hi @DataWrangler Thanks your valuable inputs. I have a question about your code
embedding_model = DatabricksEmbeddings(endpoint="databricks-bge-large-en")
You need UC enabled right ? In case that I don´t have UC enabled. Could I use HuggingFace Embeddings instead with DatabricksVectorSearch ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-26-2024 08:24 AM
bge is part of foundation models, no need for unity catalog for this. Mine is also deployed successfully.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-31-2024 03:42 PM
Hi @DataWrangler and @SwaggerP
Sorry much time without a question. But I have one. I got to load DatabricksEmbeddings. That´s ok. However my databricks admin account didn´t enabled Unity Catalog Yet. And with that I tried code you put here and When I tried the code to create Databricks Vector Search in code bellow
from databricks.vector_search.client import VectorSearchClient
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
client.create_endpoint(
name="databricks_vector_search",
endpoint_type="STANDARD"
)
[NOTICE] Using a notebook authentication token. Recommended for development only. For improved performance, please use Service Principal based authentication. To disable this message, pass disable_notice=True to VectorSearchClient().
Exception: Response content b'{"error_code":"BAD_REQUEST","message":"Unity catalog is not enabled for this account or the workspace does not have a metastore attached. Unity Catalog enablement is required for Vector Search. Please enable Unity Catalog and try again later."}', status_code 400
At this case I´m thinking to change your code to other vector search and see what happens
Any thoughts ?
At this case I´m thinking to change your code to other vector search and see what happens
Any thoughts ?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-31-2024 05:23 PM
Hi @SwaggerP . I tried to use chroma with Databricks embeddings and also had a problem.
HTTPError: 404 Client Error: Not Found for url: https://XXXXXXX/serving-endpoints/databricks-bge-large-en/invocations. Response text: {"error_code":"RESOURCE_DOES_NOT_EXIST","message":"The given endpoint does not exist, please retry after checking the specified model and version deployment exists."}
I think that is some feature not enabled on my workspace. Probably I need to deploy on Databricks Market place. However I ´m faced the issue as UC is not enabled.

Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-27-2024 08:08 AM
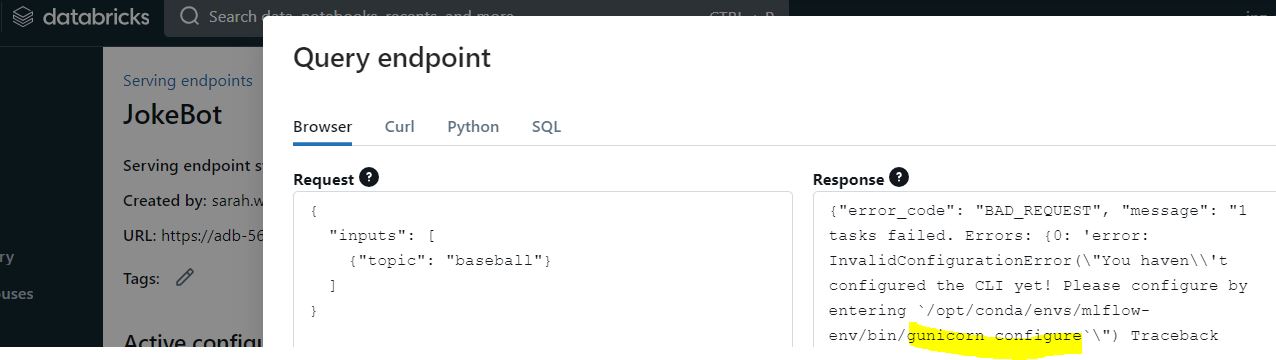
I followed the example in dbdemos 02-Deploy-RAG-Chatbot to deploy a simple joke-generating chain, no RAG or anything. Querying the endpoint produced error "You haven\\'t configured the CLI yet!..." (screenshot 1.) The solution was to add 2 environment variables (DATABRICKS_HOST and DATABRICKS_TOKEN) to the endpoint, that pull "secrets" (if you call host a secret, odd) stored using databricks-cli (screenshot 2.) See desired result in screenshot 3. This solution extrapolates to an actual RAG chain.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-27-2024 10:23 AM
Thanks @BigNaN, have you used these same variables in any other part of the code? When saving the model in the catalog did you also use these variations?
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
03-27-2024 11:19 AM
No. The only precondition to successfully querying the model serving endpoint was to have stored those secrets ahead of time, using databricks-cli, so I could use them to populate environment variables when configuring the endpoint. See https://learn.microsoft.com/en-us/azure/databricks/machine-learning/model-serving/store-env-variable...
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
04-01-2024 07:36 AM
Hi @DataWrangler and Team.
I got to solve the initial problem from some tips you gave. I used your code as base and did some modifications adapted to what I have, I mean , No UC enabled and not able to use DatabricksEmbeddings, DatabricksVectorSearch and ChatDatabricks. I did with chroma as vector search and Databricks to load a fined-tuned model. The crucial point to remove message
An error occurred while loading the model. You haven't configured the CLI yet! Please configure by entering `/opt/conda/envs/mlflow-env/bin/gunicorn configure`.
was to put DATABRICKS_HOST as environment_vars when deploy the solution
w = WorkspaceClient()
endpoint_config = EndpointCoreConfigInput(
name=serving_endpoint_name,
served_models=[
ServedModelInput(
model_name=model_name,
model_version=latest_model_version,
workload_size="Small",
workload_type="GPU_SMALL",
scale_to_zero_enabled=False,
environment_vars={
"DATABRICKS_HOST" : "{{secrets/kb-kv-secrets/adb-kb-host}}",
"DATABRICKS_TOKEN": "{{secrets/kb-kv-secrets/adb-kb-ml-token}}", # <scope>/<secret> that contains an access token
}
)
]
)
existing_endpoint = next(
(e for e in w.serving_endpoints.list() if e.name == serving_endpoint_name), None
)
serving_endpoint_url = f"{host}/ml/endpoints/{serving_endpoint_name}"
if existing_endpoint == None:
print(f"Creating the endpoint {serving_endpoint_url}, this will take a few minutes to package and deploy the endpoint...")
w.serving_endpoints.create_and_wait(name=serving_endpoint_name, config=endpoint_config)
else:
print(f"Updating the endpoint {serving_endpoint_url} to version {latest_model_version}, this will take a few minutes to package and deploy the endpoint...")
w.serving_endpoints.update_config_and_wait(served_models=endpoint_config.served_models, name=serving_endpoint_name)
displayHTML(f'Your Model Endpoint Serving is now available. Open the <a href="/ml/endpoints/{serving_endpoint_name}">Model Serving Endpoint page</a> for more details.')
Also I had to use langchain community until 0.0.25 version
pip_requirements=["mlflow==" + mlflow.__version__,"langchain_community==0.0.25","langchain==" + langchain.__version__,"sentence_transformers","chromadb"]
Because it is anoying caused by allow_dangerous_deserialization
- « Previous
-
- 1
- 2
- Next »
Announcements





{kind=link}
{kind=link}
{kind=link}
Related Content
- OBO Authentication with Unity AI Gateway and databricks.agents.deploy() in Generative AI
- Querying Metric Views via Classic/Pro SQL Warehouses in Generative AI
- Azure OpenAI v1 API support for External Model Serving / Mosaic AI Gateway? in Generative AI
- Official databricks-openai package fails to import after resolving databricks-vectorsearch in Generative AI
- Provisioned throughput is not enabled for this workspace in Generative AI