Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Machine Learning
Dive into the world of machine learning on the Databricks platform. Explore discussions on algorithms, model training, deployment, and more. Connect with ML enthusiasts and experts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
- Databricks Community
- Machine Learning
- Tuning `CrossValidator` spark job performance
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Float this Topic for Current User
- Bookmark
- Subscribe
- Mute
- Printer Friendly Page
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-03-2022 09:44 AM
I am running a 3-fold cross validation of an ML pipeline that utilizes `GBTClassifier` as the final step. It takes 18 hours to run and I am looking for feedback into how to improve the performance as I expect this to go faster.
For context here is the cluster configuration:
{
"autoscale": {
"min_workers": 1,
"max_workers": 4
},
"cluster_name": "model_training",
"spark_version": "10.3.x-cpu-ml-scala2.12",
"spark_conf": {
"spark.conf.set(\"spark.databricks.io.cache.enabled\",": "\"true\")",
"spark.databricks.delta.preview.enabled": "true"
},
"azure_attributes": {
"first_on_demand": 1,
"availability": "ON_DEMAND_AZURE",
"spot_bid_max_price": -1
},
"node_type_id": "Standard_E8_v3",
"driver_node_type_id": "Standard_E8_v3",
"ssh_public_keys": [],
"custom_tags": {},
"spark_env_vars": {},
"autotermination_minutes": 60,
"enable_elastic_disk": true,
"cluster_source": "UI",
"init_scripts": [],
"cluster_id": "0224-222219-94q7zutd"
}The below defines the pipeline:
# Define feature assembled
assembler = VectorAssembler(inputCols=feature_layers, outputCol="assembled", handleInvalid='keep')
# Define polynomial expansion on features
px = PolynomialExpansion(degree=3, inputCol="assembled", outputCol="expanded")
# Define standard scaler
standardScaler = StandardScaler(withMean=True, withStd=True, inputCol="expanded", outputCol="features")
# Define gradient boosted tree classifier
gbt = GBTClassifier(stepSize=0.3, maxIter=50)
# Define pipeline
pipeline = Pipeline(stages=[assembler, px, standardScaler, gbt])The parameter grid contains 3 parameter values for `maxDepth`. Cross Validator uses 3 folds and a parallelism of 3.
paramGrid = (ParamGridBuilder().
addGrid(gbt.maxDepth, [7, 10, 15]).
build())
crossval = CrossValidator(estimator=pipeline,
estimatorParamMaps=paramGrid,
evaluator=BinaryClassificationEvaluator(metricName='areaUnderPR'),
numFolds=3, collectSubModels=False, parallelism=3)
gbt_pipe = crossval.fit(train)Train is obtained from a dataset that has been repartitioned into 500 partitions and then 'cached':
df = df.na.drop().repartition(500)
df.cache()
df_label = df \
.withColumn("label", F.when(df["threshold_runoff"] < runoff_amount, 1).otherwise(0)) .drop("threshold_runoff")
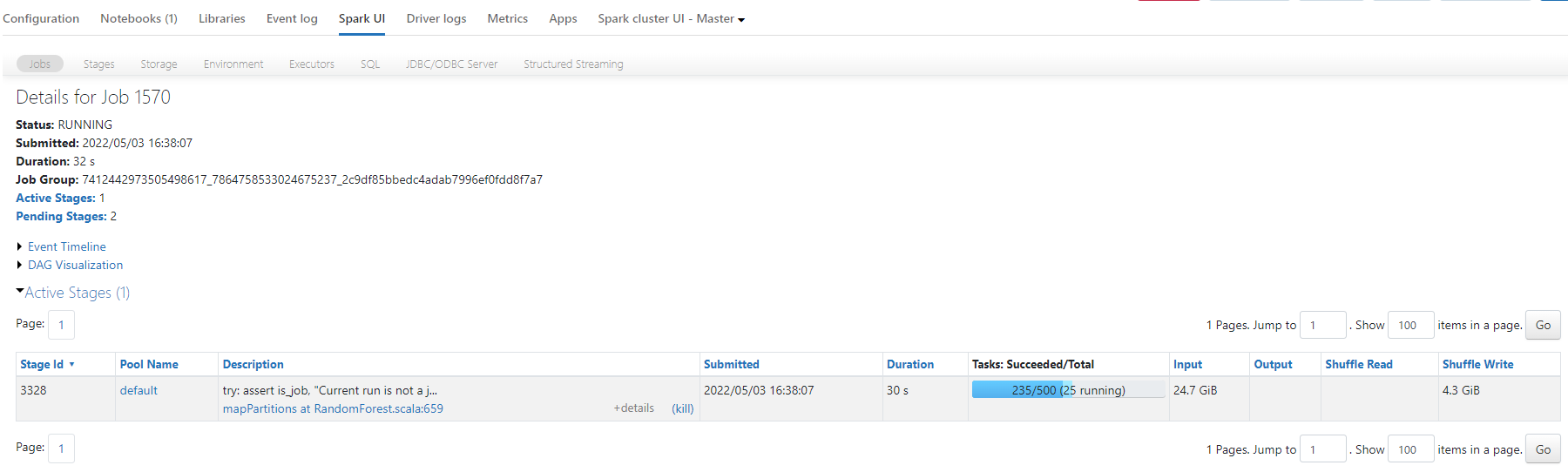
train, test = df_label.randomSplit([0.95, 0.05])Here is a screenshot of one of the jobs:

Job Summary:

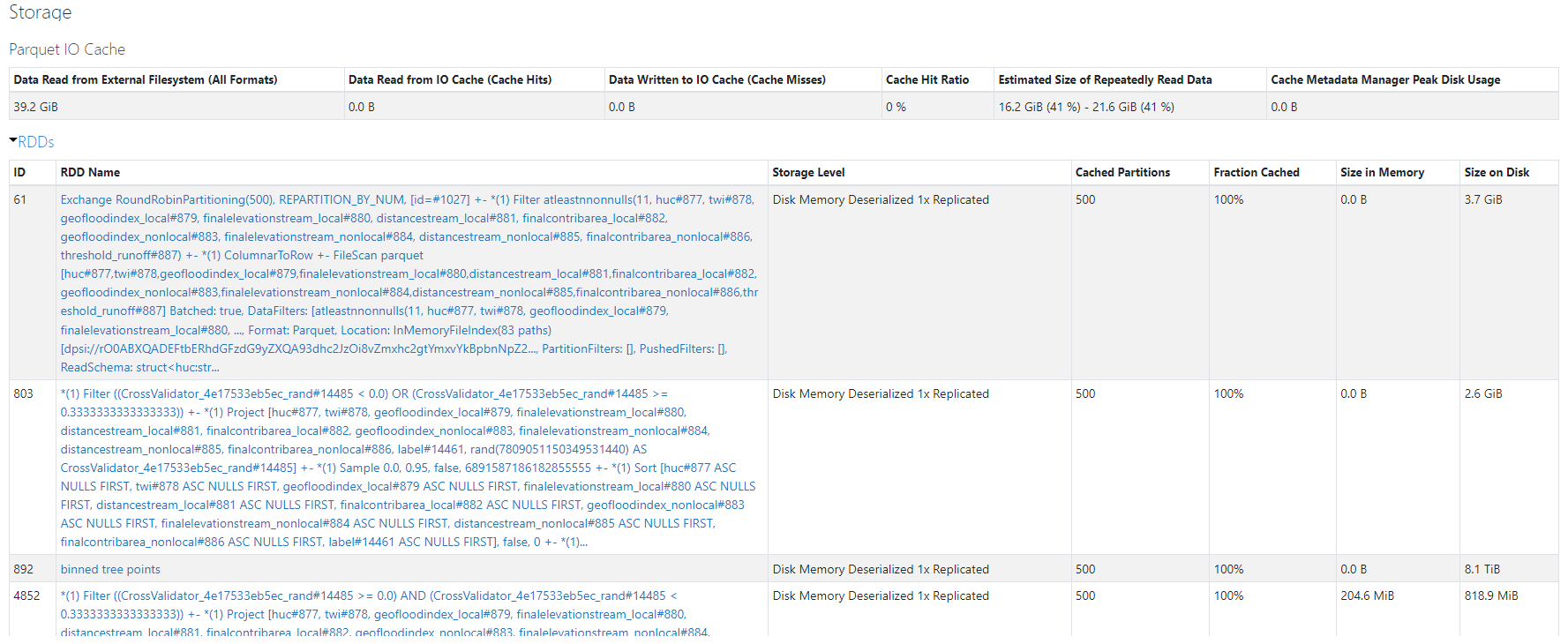
Top half of storage tab:

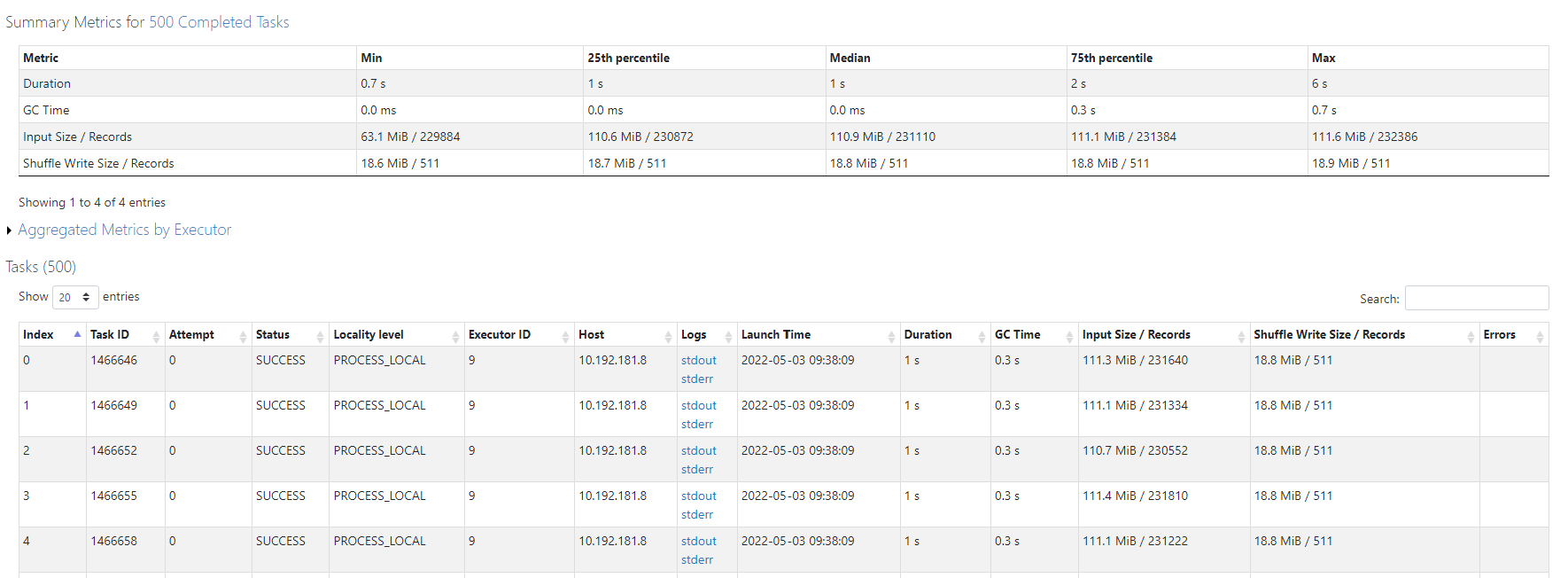
How would you go about diagnosing this issue? Any tips for performance improvements here?
I have tried increasing and decreasing the number of partitions but for a different algorithm (Logistic Regression) and 500 partitions seemed to worked quite well on the same dataset. I appreciate your input!
Labels:
- Labels:
-
Tuning


1 ACCEPTED SOLUTION
Accepted Solutions
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-11-2022 10:51 AM
Hello @Assaad Mrad ,
So this looks like trying to decide between putting the pipeline in the cross validator or the cross validator in the pipeline. Since you are doing the polynomial expansion as part of the pipeline you might want to consider putting the CV in the pipeline since it does not need to be refit each time.
So something like:
cv = CrossValidator(estimator=gbt, evaluator=evaluator, estimatorParamMaps=paramGrid,
numFolds=3, parallelism=3, seed=42)
stagesWithCV = [assembler, px, standardScalar cv]
pipeline = Pipeline(stages=stagesWithCV)
pipelineModel = pipeline.fit(trainDF)The safest way is to put the pipeline inside the CV to prevent any data leakage. But if that is not a concern then you can get some performance improvements this way.
3 REPLIES 3
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-11-2022 10:51 AM
Hello @Assaad Mrad ,
So this looks like trying to decide between putting the pipeline in the cross validator or the cross validator in the pipeline. Since you are doing the polynomial expansion as part of the pipeline you might want to consider putting the CV in the pipeline since it does not need to be refit each time.
So something like:
cv = CrossValidator(estimator=gbt, evaluator=evaluator, estimatorParamMaps=paramGrid,
numFolds=3, parallelism=3, seed=42)
stagesWithCV = [assembler, px, standardScalar cv]
pipeline = Pipeline(stages=stagesWithCV)
pipelineModel = pipeline.fit(trainDF)The safest way is to put the pipeline inside the CV to prevent any data leakage. But if that is not a concern then you can get some performance improvements this way.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
12-02-2024 01:22 AM
Hi @cchalc, I try to use synapse.ml.lightgbm and crossvalidator on databrics. But it seems there is no spark ui jobs progress bar under the notebook cells. But if I use the simple model given a fixed number of hyperparameters, it will work.
I checked the CPU utlization, it is zero. I tried to limit data into 10, it works, but take also a long time. Do you know how to fix that issue? Thanks.
Options
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-13-2022 11:09 AM
I got the response I needed. Thank you Kaniz!
Announcements




![Community [Industry BrickTalk #4] Transforming Commercial Real Estate Portfolio Management with AI](/t5/image/serverpage/image-id/25529iFB6AFAFAE433451D/image-size/large?v=v2&px=999)
{kind=link}
{kind=link}
{kind=link}
Related Content
- Databricks optimization for query perfomance and pipeline run in Data Engineering
- How to use multi-threading and batch inserts for large UPSERT to PostgreSQL from Databricks? in Data Engineering
- Leveraging AI Assistant in Data Engineering Workflows - Share Your Use Cases & Best Practices in Data Engineering
- Multi-agent chatbot Optimization in Generative AI
- Tips for Streamlining Spark Job Development and Debugging in Databricks in Warehousing & Analytics