- 2916 Views
- 2 replies
- 1 kudos
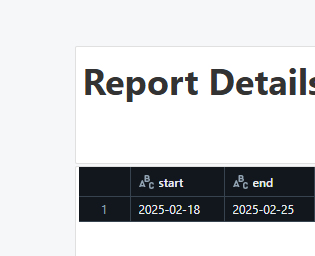
HiI think I’ve found a reproducible bug / or am misunderstanding some syntax / capabilities of Metric Views when joining a calendar scaffold to an SCD2 table.The same SQL query works perfectly, but the Metric View always returns a constant 1 per mont...
- 2916 Views
- 2 replies
- 1 kudos
Latest Reply
Hey @playnicekids , I dig some digging and have come up with some helpful hints/tips to get you past your issue:
This behavior is due to how metric view joins are defined and executed.
Diagnosis
The join in your metric view is a many-to-many te...
1 More Replies
- 2757 Views
- 4 replies
- 1 kudos
Hi there,I'm encountering the following error while attempting to read a file from R2 storage:[FAILED_READ_FILE.NO_HINT] Error while reading file r2:REDACTED_LOCAL_PART@user_id.r2.cloudflarestorage.com/data/20250128_160228_54805_wpkza_e38751cf-969e-...
- 2757 Views
- 4 replies
- 1 kudos
Latest Reply
But the error is from aws and seen when the payload size is incorrectly defined in the contentLength parameter.
Caused by: com.amazonaws.SdkClientException: Data read has a different length than the expected:
This sounds like a bug, Was this resolved...
3 More Replies