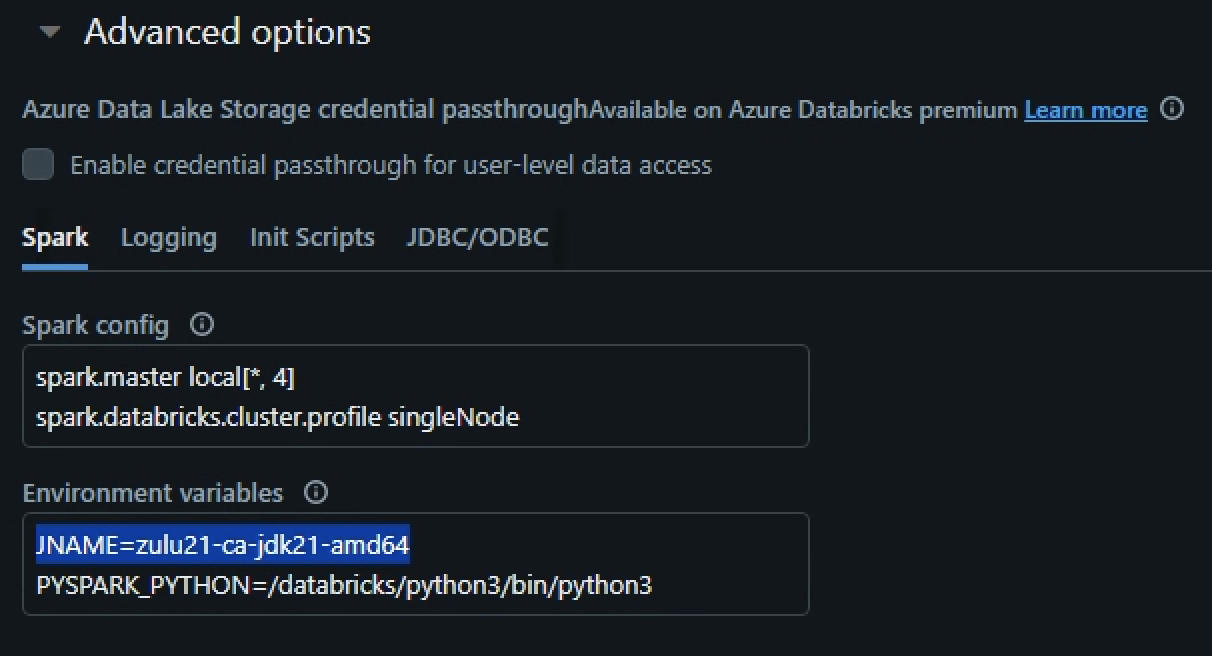
The Databricks runtime is shipped with two Java Runtimes: JRE 8 and JRE 17. While the first one is used by default, you can use the environment variable JNAME to specify the other JRE: JNAME: zulu17-ca-amd64.
FWIW, AFAIK JNAME is available since DBR 10.
We've seen use cases, which benefit from switching the JRE. Which actually makes a lot of sense, if you see which major improvement were added in the latest JREs. Having this possibility in the DBR is great.
Spark itself supports these runtimes, and with Spark 4.0 we will have official support for Java 21, which is the current LTE release.
My questions would be:
* What is Databricks strategy on the Java Runtimes?
* What is the reason that Databricks still ships JRE 8 as default, while competitors like MS Fabric decided to use newer version by default.
* The new version of Spark (Spark 4.0) is just around the corner, and Databricks supports some of these new features already today (like PySpark DataSources or Variant type). Which is awesome! What about Java 21, when will we able to use this version in DBR?







{kind=link}