- 12671 Views
- 2 replies
- 8 kudos
Turning Databricks into an AI pair‑programmer with Claude‑powered coding agents
Databricks + Claude Code This guide walks through a practical, end‑to‑end setup: installing Claude Code, wiring it to Anthropic models served from Databricks, and configuring authentication so everything “just works” from your terminal and editor. Yo...
- 12671 Views
- 2 replies
- 8 kudos
- 8 kudos
I have yet to use Claude within Databricks - Thanks for this @pradeep_singh
- 8 kudos
- 682 Views
- 0 replies
- 1 kudos
Hive (Dark) Metastore — Azure Databricks Standard Tier Retirement is a great move
Retirement is planned for Azure in Oct 2026. Completed in other clouds in Oct 2025Data residing in the Hive Metastore is opaque, suffers from low governance and is siloed in legacy technical constructs. The Hive Metastore (HMS) was a technology revol...
- 682 Views
- 0 replies
- 1 kudos
- 808 Views
- 0 replies
- 0 kudos
You can use built-in AI functions directly in Databricks SQL
Databricks provides built-in AI functions that can be used directly in SQL or notebooks, without managing models or infrastructure.Example:SELECT ticket_id, ai_generate( 'Summarize this support ticket:\n{{text}}', 'databricks-dbrx-instruct', descript...
- 808 Views
- 0 replies
- 0 kudos
- 830 Views
- 2 replies
- 8 kudos
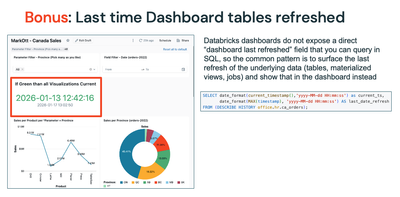
How can I tell my Dashboard visualizations aren't stale?
With AI/BI Dashboards, a best practice is for the creator/owner to 'Schedule' the Dashboard to rerun the underlying datasets when changes have occurred. This ensures the Visualizations are rendered with the freshest data. But users still will questi...
- 830 Views
- 2 replies
- 8 kudos
- 8 kudos
@mark_ott That is a nice idea and quite useful. Quick question: how did you define 'stale' data in your case? So what is the threshold at which your 'conditional equation' color codes the date red? did you somehow link that to the refresh schedule?
- 8 kudos
- 2447 Views
- 2 replies
- 6 kudos
Data + AI Is Not the Future at Databricks. It’s the Present.
One thing becomes very clear when you spend time in the Databricks community: AI is no longer an experiment. It is already part of how real teams build, ship, and operate data systems at scale.For a long time, many organizations treated data engineer...
- 2447 Views
- 2 replies
- 6 kudos
- 6 kudos
Thanks @Louis_Frolio for your kind words. Happy to contribute here.
- 6 kudos
- 11704 Views
- 3 replies
- 6 kudos
Getting Databricks Generative AI Engineer Associate (and What I Learned)
I just earned my Databricks Certified Generative AI Engineer Associate Certification, and in this post, I’m sharing the key tips, resources, and personal insights that helped me succeed. My certiticate from DatabricksNavigation:PreludeAbout the certR...




- 11704 Views
- 3 replies
- 6 kudos
- 6 kudos
Hey @devipriya , thanks for sharing your notes on how you found success with the certification(s). Appreciate you taking the time to pass along what worked for you. Cheers, Louis
- 6 kudos
- 1262 Views
- 2 replies
- 3 kudos
Change default workspace access to Consumer access
When Databricks One was launched, the default behaviour of the system-managed users group was a major issue. Since every new user is automatically added to users group, and that group traditionally came with "Workspace Access" entitlements, admins ha...
- 1262 Views
- 2 replies
- 3 kudos
- 3 kudos
Thanks @Advika. it was certainly a big win for my env.
- 3 kudos
- 359 Views
- 0 replies
- 3 kudos
Very short video on tip about Collect() method!!!
Here is a very short video on how to use collect() method with caution as it could overwhelm the cluster in some big data scenarios!!!! Now only in Spanish but I guess youtube will do the trick to translate into very correct English xDD
- 359 Views
- 0 replies
- 3 kudos
- 4192 Views
- 3 replies
- 6 kudos
A Governance-First Unified Namespace:Why Manufacturers Need Unity Catalog to Scale Industry 4.0 Data
The Industrial Data ChallengeManufacturing enterprises today operate with a fundamental paradox: they're drowning in data yet starving for insights. A typical plant generates terabytes of information daily across dozens of systems—from shop floor PLC...

- 4192 Views
- 3 replies
- 6 kudos
- 671 Views
- 0 replies
- 0 kudos
Great Expectations with Fabric and Databricks-Building Bulletproof Data Pipelines
In this article, I’ll walk you through transforming a basic PySpark notebook into a production-ready data pipeline with comprehensive quality checks using Great Expectations patterns in Microsoft Fabric and Databricks. We’ll start simple and progress...

- 671 Views
- 0 replies
- 0 kudos
- 691 Views
- 1 replies
- 1 kudos
Dashboards deployment
It is finally possible to deploy dashboards using DABS and change the catalog and schema. It is solving the biggest problem with bringing the dashboard to production. New parameters for the dashboard resource were added: dataset_catalog and dataset...

- 691 Views
- 1 replies
- 1 kudos
- 1 kudos
@Hubert-Dudek - This was really a much-awaited feature. Eventually DAB must cover all developed assets which requires promotion to higher environment to cover the CICD seamlessly.
- 1 kudos
- 1321 Views
- 1 replies
- 2 kudos
SQL Scripting - Procedural Logic in Databricks SQL (Without Leaving SQL)
We've all been there. You need to loop through a list of tables, apply some transformation, handle a few edge cases, and maybe catch an error or two. In most data platforms, that means switching to Python or Scala—even if 90% of your logic is just SQ...
- 1321 Views
- 1 replies
- 2 kudos
- 2 kudos
Correction: Preview is available on Databricks Runtime 16.3 and above.
- 2 kudos
- 5241 Views
- 0 replies
- 2 kudos
Databricks Serverless Compute: Performance, Cost, and Time-to-Value Explained
As data platforms mature, the focus is no longer just scalability—it is about speed, simplicity, and cost efficiency. Engineering teams want to deliver insights faster without managing infrastructure, while organizations want predictable costs and st...

- 5241 Views
- 0 replies
- 2 kudos
- 889 Views
- 1 replies
- 1 kudos
Window Functions in Metrics Views
The latest update for the first week of 2026 is the addition of window functions in Metrics View. In enterprises, there are always measures like cumulative sales or rolling forecast, so it is really important that we can use window functions in busin...

- 889 Views
- 1 replies
- 1 kudos
- 1 kudos
@Hubert-Dudek - Thanks for sharing these bite-size updates as these get lost in many release-notes. Keep it up.
- 1 kudos
- 363 Views
- 0 replies
- 2 kudos
Mix Shell with Python
Assigning the result of a shell command directly to a Python variable. It is my most significant finding in magic commands and my favourite one so far. Read about 12 magic commands in my blogs: - https://www.sunnydata.ai/blog/databricks-hidden-magic-...

- 363 Views
- 0 replies
- 2 kudos
-
Access Data
1 -
Access Delta Tables
1 -
ADF Linked Service
1 -
ADF Pipeline
1 -
Advanced Data Engineering
6 -
agent bricks
2 -
Agentic AI
3 -
AI
3 -
AI Agents
5 -
AI Readiness
1 -
AIBI
1 -
Analytics
1 -
Analytics Engineering
1 -
Apache spark
3 -
Apache Spark 3.0
2 -
ApacheSpark
1 -
Architecture
5 -
Associate Certification
2 -
Audit
1 -
Auto-loader
1 -
Automation
1 -
AWSDatabricksCluster
2 -
Azure
3 -
Azure databricks
3 -
Azure Databricks Delta Table
1 -
Azure Databricks Job
2 -
Azure Delta Lake
3 -
Azure devops integration
1 -
Azure Unity Catalog
2 -
AzureDatabricks
2 -
BI
1 -
BI Integrations
1 -
Big data
1 -
Billing and Cost Management
2 -
Blog
1 -
Caching
2 -
CDC
3 -
CDF
1 -
Certification
1 -
Certification Badge
1 -
Certification Exam
1 -
CICD
2 -
CICDForDatabricksWorkflows
1 -
Cluster
1 -
Cluster Policies
1 -
Cluster Pools
1 -
Collect
1 -
Community Event
1 -
CommunityArticle
2 -
Cost Optimization Effort
2 -
CostOptimization
2 -
custom compute policy
1 -
CustomLibrary
1 -
DABs
1 -
DAIS 0206
3 -
DAIS 2026
2 -
Dashboards
2 -
Data
1 -
Data Analysis with Databricks
1 -
Data Architecture
2 -
Data Driven AI Roadmap
1 -
Data Engineering
16 -
Data Governance
5 -
Data Ingestion
2 -
Data Ingestion & connectivity
1 -
data layout
1 -
Data Mesh
1 -
data optimization
1 -
Data Processing
1 -
Data Quality
2 -
Data warehouse
1 -
Data Warehousing
1 -
databricks
3 -
Databricks App
1 -
Databricks Apps
2 -
Databricks Assistant
2 -
Databricks Certified
1 -
Databricks Community
1 -
Databricks Dashboard
2 -
Databricks Delta Table
2 -
Databricks Demo Center
1 -
Databricks genAI associate
1 -
databricks genie
1 -
Databricks Job
2 -
Databricks Lakeflow
3 -
Databricks Lakehouse
2 -
Databricks Migration
3 -
Databricks Mlflow
1 -
Databricks News
1 -
Databricks Notebooks
1 -
Databricks Pyspark
3 -
Databricks Serverless
1 -
Databricks Support
1 -
Databricks Training
1 -
Databricks Unity Catalog
3 -
Databricks Workflows
3 -
DatabricksAutomation
1 -
DatabricksML
1 -
DatabricksOptimization
1 -
DataEngineering
1 -
DBR Versions
1 -
Declartive Pipelines
2 -
DeepLearning
1 -
Delta Lake
11 -
Delta Lake Files
1 -
Delta Live Table
2 -
Delta Live Tables
1 -
Delta Time Travel
1 -
Delta-lake
1 -
DeltaLake
1 -
DevOps
2 -
DimensionTables
1 -
DLT
2 -
DLT Pipelines
3 -
DLT-Meta
1 -
Dns
1 -
Dynamic
1 -
ETL Pipelines
2 -
fastapi
1 -
Free Databricks
3 -
Free Edition
1 -
GenAI
1 -
GenAI agent
2 -
GenAI and LLMs
4 -
GenAIGeneration AI
2 -
Generation AI
1 -
Generative AI
2 -
Generative AI Engineer
1 -
Genie
3 -
Git
1 -
Google Bigquery
1 -
Google cloud
1 -
Governance
2 -
Governed Tag
1 -
hackathon
1 -
Hive metastore
1 -
Hubert Dudek
42 -
Hybrid Lakehouse
1 -
Kafka streaming
2 -
LakeBase
4 -
Lakeflow
1 -
Lakeflow Pipelines
1 -
Lakehouse
3 -
Lakehouse Migration
1 -
Langchain
1 -
LangGraph
1 -
Lazy Evaluation
1 -
Learning
1 -
Library Installation
1 -
Lineage
2 -
LiquidClustering
2 -
Live Tables CDC
1 -
Llama
1 -
LLM
1 -
LLMs
1 -
Machine Learning
1 -
mcp
2 -
Medallion Architecture
3 -
MERGE Performance
2 -
Metadata
2 -
Metric Views
2 -
Microsoft Teams
1 -
Migration
1 -
Migrations
1 -
mosic ai search
1 -
MSExcel
3 -
Multi-Table Transactions
1 -
Multiagent
3 -
Networking
2 -
New Features
1 -
NotMvpArticle
1 -
Optimize Command
1 -
Partitioning
3 -
Partner
1 -
Performance
2 -
Performance Tuning
3 -
PII
1 -
Powerbi
1 -
PredictiveOptimization
1 -
Private Link
1 -
Pyspark
6 -
Pyspark Code
1 -
Pyspark Databricks
1 -
Pytest
1 -
Python
1 -
Reading-excel
2 -
Row Level Security
1 -
SAP
2 -
Sap Hana Driver
1 -
Scala Code
1 -
Scd Type 2
1 -
Scripting
1 -
SDK
1 -
Security
1 -
Semantic Layer
1 -
Serverless
2 -
slack
1 -
Spark
6 -
Spark Caching
1 -
Spark Performance
1 -
SparkSQL
1 -
SQL
3 -
Sql Scripts
2 -
SQL Serverless
1 -
streaming
1 -
streamlit
1 -
Structured streaming
1 -
Students
2 -
Support Ticket
1 -
Sync
1 -
Training
1 -
Tutorial
3 -
UCSD
1 -
Unit Test
1 -
Unity Catalog
12 -
Unity Cataloge
1 -
Unity Catlog
1 -
University Alliance
1 -
VACUUM Command
1 -
Variant
1 -
Warehousing
1 -
Workflow Jobs
1 -
Workflows
9 -
Zerobus
2 -
Zordering
1
- « Previous
- Next »
| User | Count |
|---|---|
| 85 | |
| 75 | |
| 69 | |
| 63 | |
| 44 |